저는 평상시에 서버개발에 주로 Java, Kotlin, Spring 조합을 사용하던 "Java 2명 타요"중 1명에 속하는 사람이었습니다.
Java + Spring의 개발 직관성과 생산성은 정말 사랑할 수밖에 없다 생각하거든요!

그럼에도 다른 언어 진영의 서버사이드 프레임워크들이 항상 궁금했었습니다. 스프링이 편한 것을 알기 위해서는 다른 도구들이 불편한 것을 알아야 그 대비적 효과가 더 크다 생각하기 때문입니다(?)
다행히 학기 초반에 일주일 정도의 여유시간이 생겼으며, 그나마 언어는 알고 있는 Python 진형의 기술인 DRF를 공부해 보는 시간을 갖게 되었습니다....... 만.....
한 10일 정도 공부해 보고 느낀 점은... 음... 할 말이 많아지는 기술이더군요.... 따라서 제가 직접 느낀 DRF의 경험을 공유해보려 합니다.
혹여나 잘못된 내용이 있다면 댓글로 알려주시면 감사하겠습니다!
1. 짤막한 DRF 소개
Python이 뭔지는 다들 당연히 아실 거고, 그럼 DRF가 뭔지 짧게 살펴봅시다~
우성 공식문서를 보면 다음과 같이 적혀 있는데,
Django REST framework is a powerful and flexible toolkit for building Web APIs.
즉, "Django안에서 Web RESTful 한 API 서버를 쉽게 구축할 수 있도록 도와주는 도구"라고 할 수 있습니다.
이러한 DRF는 태생이 Django로부터 출발하기 때문에 다음과 같은 Django의 특징을 그대로 따라가게 됩니다.
- Don't repeat yourself (DRY) : Django는 중복을 최소화하고 유지 관리를 간소화하기 위해 재사용 가능한 코드 구성 요소와 추상화를 장려합니다.
- 느슨한 결합 : Django의 구성 요소는 가능한 독립적으로 설계되어 유연성을 증진하고 개별 구성 요소를 교체하거나 수정하는 데 어려움이 없도록 합니다.
- 빠른 개발 : Django는 웹 개발 프로세스를 단순화하고 효율적으로 만들기 위해 노력하며, 개발자들이 웹 애플리케이션을 빠르고 효율적으로 구축하고 배포할 수 있도록 합니다.
- 명시적인 것이 암시적인 것보다 낫다 : Django는 명확하고 명시적인 코드를 선호하며, 암묵적인 동작보다 명시적인 코드를 사용함으로써 개발자가 코드베이스를 이해하고 유지 관리하기 쉽도록 합니다. (뒤에 말하겠지만... serializer를 사용하면서 전혀 명시적이다고 느끼지 못하게 되었던 기억이...)
또한 원래 Django는 MTV(Model-View-Template)를 주로 사용하는데, DRF를 사용하면 Template(Spring으로 치면 Thymeleaf)을 사용하기보다는 Serializer를 사용하여 Json 형식의 응답을 주로 만들게 되는데,
이때 API 기반 개발을 위해서 view 구현체는 다른 Django 라이브러리인 DRF에 위임하게 된 것입니다.
DRF는 대표적인 Class Bassed View(다음 단락에서 설명) 구현체에 특화적인 라이브러리입니다.
물론 일부 Function Based View 방식으로 DRF도 개발을 진행할 수는 있지만, DRF는 오랜 기간 Class Bassed View에 치중하여 구현된 도구입니다. 따라서 DRF를 사용하게 된다면 Function Based View 보다는, Class Bassed View를 사용하는 것이 권장사항에 해당됩니다.
2. DRF와 좌충우돌 여행기
2-1) Class-based-view(CBV)와 Function-based-view(FBV)
▶ Function Bassed View (FBV)
Spring만 사용하다 보면 사실 대부분 FBV 방식으로 View(표현계층)을 구현하는 것이 일반적입니다.
아주 직관적이면서, 추가로 알아야 할 사항이 많지는 않기 때문입니다.
물론 Python Django에서도 이러한 FBV방식을 지원하기는 합니다.
@api_view(['GET', 'POST'])
def contact(request):
if request.method == 'POST':
# Code block for POST request
else:
# Code block for GET request (will also match PUT, HEAD, DELETE, etc)대표적으로 요즘 Python진영에서 인기가 급상승하고 있는 FastAPI 가 이러한 FBV의 대표적인 주자라고 할 수 있으며,
사실 Spring을 사용해 왔던 개발자라면 위와 같은 코드 스타일에 크게 거리감을 느끼지는 않을 것입니다.
그럼 이제 CBV에 대하여 알아볼까요?
▶ Class Bassed View (CBV)
CBV는 Django가 제공해 주는 MixInView(? 당장은 뭔지 모르셔도 돼요) 구현체나 자신이 직접 만든 MixInView(?)를 상속하여 원하는 메서드만 오버라이딩 하여 개발하는 방식입니다.
Spring에서 JDBC Template를 사용해 본 사람이라면 알 텐데, 대부분의 기능은 Template가 진행해 주고 우리가 원하는 SQL문과 반환타입 정도를 지정해 주는 작업을 하게 되는데, 여기서 JDBC Template을 일종의? MixInView라고 생각할 수 있습니다.
(100% 동일하다는 거 아니에요!, 느낌이 비슷하다 정도~)
대부분의 기능은 MixInView가 갖고 있고, 필요한 부분만 오버라이딩 하여 레고 블록을 조립하듯 사용하는 방식이죠.
이러한 CBV는 FBV에 비하여 매우 적은 코드 라인의 수로 동일한 기능을 구현할 수 있도록 도와줍니다.
다만 저는 이게 장점인지는 모르겠더라고요?
코드수가 적다 -> 개발 속도가 빠르다 -> 좋다??? 스타트업에 해당되려나???
여하튼, CBV는 서로 비슷한 성격의 View를 Class로 묶어 군집을 만들어 사용하는데, 이러한 DRF의 View 구현체가 ViewSet입니다.
어렵다고요?? 정상입니다. 좀 더 직관적으로 알기 위해 코드로 살펴봅시다!
우선 CBV로 구현한 API를 살펴봅시다. (urls 매핑, model 매핑 과정 전부 생략)
class UserClassBasedViewSet(
mixins.CreateModelMixin,
mixins.ListModelMixin,
mixins.UpdateModelMixin,
viewsets.GenericViewSet
):
queryset = User.objects.all()
serializer_class = UserSerializer
permission_classes = [IsAuthenticated] # 인증된 사용자만 접근 가능위 코드만으로 (리스트 조회, 단건 조회, 객체 생성, 업데이트, 부분 업데이트, 삭제)가 전부 가능하게 됩니다.
UserClassBasedViewSet은 DRF가 제공해 주는 ViewMixin 구현체를 상속받는 것만으로도 실제 동작하는 API를 제공해 줍니다.
즉, DRF를 사용하면 API를 하나하나 개별적으로 구현하지 않아도 되게 됩니다. 더 나아가 DRF가 생성해 주는 API들은 자동적으로 REST 아키텍처를 준수하게 되는 장점도 있습니다.
이를 만약 FBV로 구현했다면 다음과 같을 것입니다.
class StoreViewSet(viewsets.GenericViewSet):
def list(self, request, *args, **kwargs) -> Response:
# 상점 목록 조회하는 코드를 직접 구현
return Response(...)
def retrieve(self, request, *args, **kwargs) -> Response:
# 상점 상세 조회하는 코드를 직접 구현
return Response(...)
def create(self, request, *args, **kwargs) -> Response:
# 상점 생성하는 코드를 직접 구현
return Response(...)
def update(self, request, *args, **kwargs) -> Response:
# 상점 수정하는 코드를 직접 구현
return Response(...)
def partial_update(self, request, *args, **kwargs) -> Response:
# 상점 일부 수정하는 코드를 직접 구현
return Response(...)
def destroy(self, request, *args, **kwargs) -> Response:
# 상점 삭제하는 코드를 직접 구현
return Response(...)
생산성의 차이가 느껴지시나요? 이처럼 DRF는 대부분의 작업을 이미 자기가 정의한 방식으로 수행하게 됩니다.
하지만 위 CBV방식에서 느낄 수 있듯, Django가 다 알아서 해주는 방식이 간단한 API면 모를까...
요구사항이 복잡해지는 경우에는 원하는 작업을 override 하여 작업하게 됩니다.
예를 들어 특정 단건 정보를 조회하는 API에 pagination 기능을 추가하고 싶다고 해봅시다!
그러면 기존에 DRF의 RetrieveAPIView에 있던 retrive를 다음과 같이 오버라이드 해줘야 합니다.
class PostRetrieveAPIView(RetrieveAPIView): # RetriveAPIView를 상속함
queryset = Post.objects.all()
serializer_class = PostDetailSerializer
def retrieve(self, request, *args, **kwargs): # 오버라이딩
instance = self.get_object()
prevInstance = get_prev_next(instance)
nextInstance = get_next_next(instance)
commentList = instance.comment_set.all()
data = {
'post': instance,
'prevPost': prevInstance,
'nextPost': nextInstance,
'commentList': commentList,
}
serializer = self.get_serializer(instance=data)
return Response(serializer.data)
def get_prev_next(instance):
try:
prevInstance = instance.get_previous_by_update_dt()
except instance.DoesNotExist:
prevInstance = None
return prevInstance
def get_next_next(instance):
try:
nextInstance = instance.get_next_by_update_dt()
except instance.DoesNotExist:
nextInstance = None
return nextInstance
위 코드에서는 RetrieveAPIView를 상속하여 메서드를 오버라이딩 하고 있습니다.
RetrieveAPIView는 다음과 같이 1. RetrieveModleMixin, 2. GenericAPIView를 상속하고 있으며,

우리가 오버라이딩 한 retrieve는 RetrieveModleMixin에 구현되어 있음을 알 수 있습니다.

즉, 기능을 추가하기 위해서는
- 해당 기능을 어느 Method에 추가해야 하는지 사전에 알고 있어야 합니다.
- 해당 Method를 오버라이드 하기 위해 어떤 Class를 상속받아야 하는지 알고 있어야 합니다.
이처럼 DRF의 CBV는 자기가 오버라이딩 할 Class들을 에 대한 사전 지식이 있어야 효율적으로 구현할 수 있습니다.
이는 당연한 것이 하나하나 API를 다 구현하는 것보다 Django가 대부분을 해주기 때문에, 그만큼 학습해야 할 부분이 많아졌다는 것이 될 것입니다.....
이것만 해도 저는 사실... DRF보다는 직관적인 Spring이 더 편하다 생각되더라고요?
하지만 고비는 이게 끝이 아니었으니....
2-2) Serializer 너는 또 뭐냐?
Spring의 jackson 라이브러리님 정말 감사합니다. 무조건 감사하다고요!
DRF의 serializer는 이름 그대로 객체를 직렬화하는 역할을 한다. 하지만 단순히 직렬화만 하는 것 이 아니라 다음과 같은 다양한 기능을 수행한다.
- 데이터 직렬화 : serizalization
- 데이터 검증 : validate
- 데이터 저장 : create & update
- API 스키마 모델링 : schema
처음에는 단순하게 객체 <-> Json 변환기인 줄 알았는데, 생각보다 더 해주는 기능이 많더라고요.....
Spring으로 치면 약간 (DTO + 검증 기능 + 객체 업데이트 로직) 다 추가되어 있는 기분이랄까??? 근데 이게 좋은 건가??
그 유명한 단일책임 원칙(SRP) 바로 무시해 버리는 기술인 것 같은데...?
사실 직렬화 하는 과정부터 약간? 도망치고 싶긴 했습니다.... 만.. 조금만 더 버텨봅시다...
다음과 같은 Json 파일이 있다고 해봅시다.
{
"name": "Shine",
"age": 999,
"company": {
"name": "konkuk univ",
"company_number": "111-111-111",
},
"is_deleted": False,
"birth_date": "1896-03-15",
"employment_period": 3.75,
"programming_language_skill": ["python", "Java", "C++"],
"department" 3,
}company 같은 경우 데이터 타입이 Object이다. 따라서 JSON을 객체에 매핑시킬 CompanySerializer를 따로 만들어줘야 합니다!
CompanySerializer의 birth_date는 문자열로 넘어올 때 datetime으로 취급되어야 하기 때문에 serializer.DateField()를 선언해줘야 하거든요!
이처럼 serializer로 Json -> Object로 역직렬화하기 위해서는 다음과 같이 serializer를 구현해줘야 합니다...
class CompanySerializer(serializers.Serializer):
name = serializers.CharField()
company_number = serializers.CharField()
class EmployeeSerializer(serializers.Serializer):
name = serializers.CharField()
age = serializers.IntegerField()
company = CompanySerializer()
is_deleted = serializers.BooleanField()
birth_date = serializers.DateField(format="%Y-%m-%d")
employment_period = serializers.FloatField(help_text="재직 기간 ex: 3.75년")
programming_language_skill = serializers.ListField(child=serializers.CharField())
department1 = serializers.PrimaryKeyRelatedField(queryset=Department1.objects.all())
def create(self, validated_data: dict[str, Any]) -> Employee:
print(validated_data["name"])
print(validated_data["age"])
print(validated_data["company"])
print(validated_data["is_deleted"])
print(validated_data["birth_date"])
print(validated_data["employment_period"])
print(validated_data["programming_language_skill"])
print(validated_data["department1"])
return Employee.objects.first()
?????? 응?????
run 합시다... (진심입니다 저 스스로가 Human Jackson 라이브러리가 된 기분이랄까? 내가 이걸 왜 매핑하고 있는 읍읍...)
사실, 단일 Model(Spring으로 치면 Entity)로 매핑하는 경우 좀 더 손쉽게 ModelSerializer를 상속하면 간편하게 되기는 하는데,
제 경험상, API로 받은 Dto를 Model 자체로 1대 1 매핑하는 경우는 드문 케이스에 해당됐었습니다... toy project라면 모를까...
이러한 배경에는 Python은 근본적으로 동적 타입 언어이기 때문일 것입니다.
변수의 자료형을 지정하지 않고 단순히 선언하는 것만으로도 값을 지정할 수 있기 때문에, 변수의 자료형은 코드가 실행되는 시점에 결정되죠.
즉, 실행하는 시점에 변환해줘야 하기 때문에 이러한 Serializer가 필요한 것이 아닐까? 하는 추측을 남겨봅니다.
Json은 단순 문자열이기에 실행시점에 타입을 지정해 놓은 Serializer가 없다면 해당 Json을 어떻게 해석해야 할지 모를 것이 분명하다 생각합니다!
이제 끝난 줄 알았죠? 아직 할 말 많습니다 ㅎㅎㅎ
2-3) Serializer의 데이터 저장? 너가 create까지 한다고? 아니 심지어 update까지?
Serializer는 create() 메서드와 update() 메서드를 구현해서 사용할 수 있습니다.
다만, create(), update()를 직접적으로 호출하는 방식이 아니라, save() 메서드를 호출하면 Serializer가 전달받은 Request를 기반으로 인스턴스를 생성할 때 넘겨받은 argument에 따라서 create()가 호출될지? update()가 호출될지? 가 결정되는 방식이더군요...
나 모르는 게 해주는 게 참 많은 아이인 것 같아요...
- save() 메서드 호출 시에 로직이 나눠지는데,
- 1) 만약 API로 받은 요청 데이터를 통해 DB에서 가져온 인스턴스가 없다면 -> create() 호출
- 2) 만약 API로 받은 요청 데이터가 존재하고, DB에서 가져온 인스턴스도 존재한다면 -> update() 호출
즉, 코드로 살펴보면 다음 코드의 경우 data만 전달하니 create()로 판단하고,
serializer = XXXSerializer(data = request.data) # data만 전달받는 경우
serializer.is_valid(raise_exception=True)
serializer.save()
다음 코드의 경우 data과 DB로부터 찾아온 인스턴스 또한 전달받으니 update()로 판단하게 됩니다.
serializer = XXXSerializer(data = request.data, instance = instance)
serializer.is_valid(raise_exception=True)
serializer.save()
위에서 사용한 XXXSerializer를 다음과 같이 구현해 두었습니다.
class XXXSerializer(serializers.Serializer): # Serializer를 상속
def create(self, validated_data) -> Order: # 오버라이딩
# 어떤 생성 작업
pass
def update(self, instance, validated_data) -> Order: # 오버라이딩
# 어떤 수정 작업
passSerializer를 상속하여, create()와 update()를 저의 방식으로 오버라이딩 했다 생각하시면 됩니다!
또한, save() 메서드의 함수 본문 구현체를 보면 다음과 같이 self.update(), self.create()가 호출되는데,
우리는 우리가 원하는 방식으로 오버라이딩 했으니, save()를 호출하면 우리가 새롭게 정의한 create, update로직이 수행되게 됩니다!

자기가 알아서 다 큰 흐름을 정해주었고, 개발자는 일부 메서드만 오버라이드 하는 방식인 CBV의 장점(?)이 느껴지는 순간이었습니다!!
2-4) 데이터를 관리하는 주체가 Django다?
Django에는 AddField라는 키워드가 있습니다.
일단 다음 코드를 살펴보면, Defualt 값을 지정해주고 있습니다~
migrations.AddField(
model_name='amodel',
name='a_111_field',
field=models.fields.CharField(
defualt='shine', max_length=32 # 기본값 지정
),
),
AddField는 Django 필드에 명시된 옵션 값을 기반으로 하여 다음과 같이 새로운 칼럼을 생성하고 있군요~
ALTER TABLE 'b_model' ADD COLUMN 'a_111_field' varchar(32) default 'aa' NOT NULL;
ALTER TABLE 'b_model' ALTER COLUMN 'a_111_field' DROP DEFAULT;
AddField는 DDL이 하나 더 생성되는 것을 확인할 수 있는데, Django 필드에 default='aa'라는 옵션을 부여했는데, 왜 2번째 DDL을 추가해서 굳이 DROP DEFAULT를 하는 것인지? 한 번에 이해하기는 어려웠습니다.... (사실 마법처럼 보였습니다... 이는 Django ORM의 특징을 알아야 이해 가능하더군요).. 이것 덕분에 하루는 불태운 것 같습니다... 왜 이러한 선택을 하게 된 것 인지.. 하... 진짜 Django.. 너란 녀석...
Django ORM은 데이터에 대한 모든 제어권을 Django가 전부 갖고 있기를 원한다.
즉, 그림으로 이해하면 다음과 같아요!
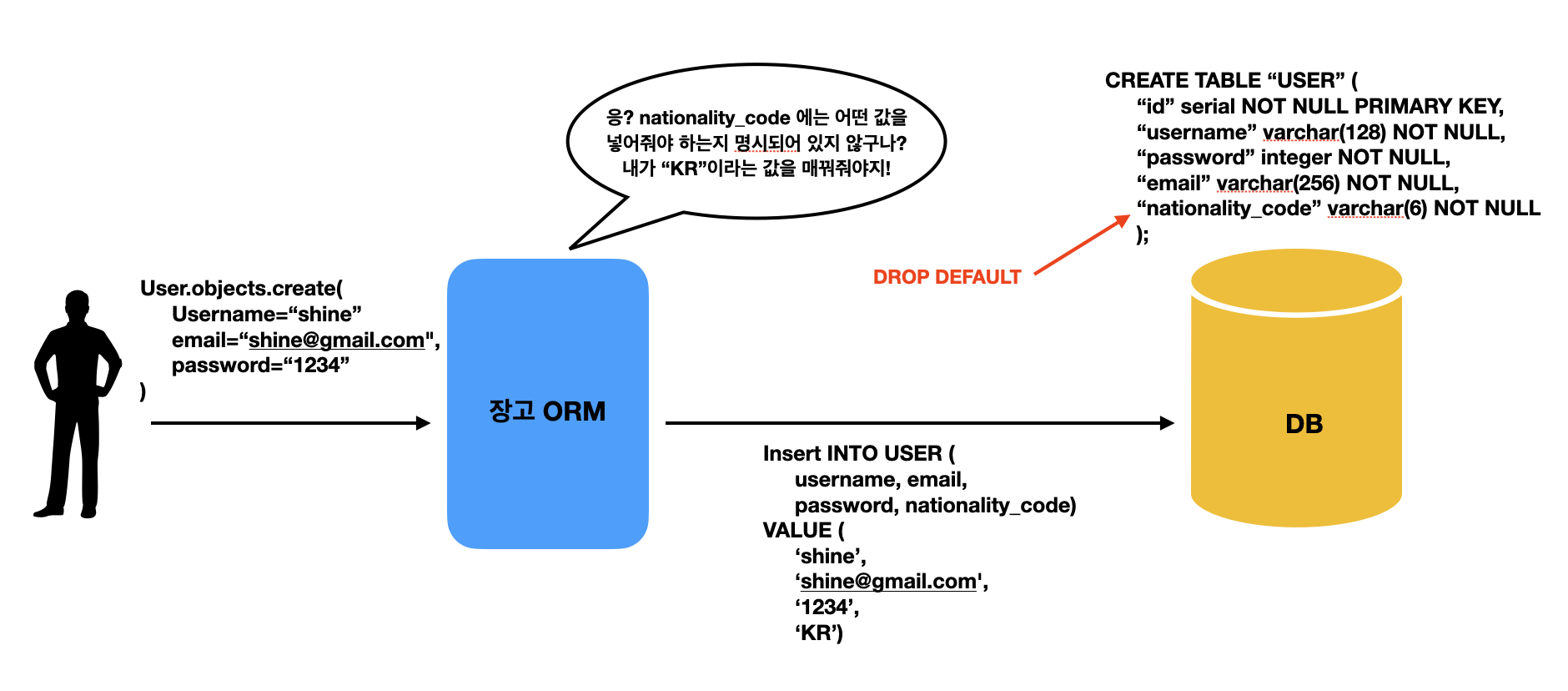
위 그림처럼 DEFUALT라는 옵션을 제어하는 주체가 다르다. Django는 DB에 입력하는 데이터를 스스로 제어하고 싶어 합니다!
장고는 자기가 일지 못하는 기본값이 DB에 의해 설정되는 것을 원하지 않기 때문에, AddField가 수행될 때 ALTER TABLE "b_model" ALTER COLUMN 'a_111_field" DROP DEFAULT;라는 쿼리를 추가하여 DB에 이미 만들어진 Default 옵션을 제거하는 DDL 1줄을 추가적으로 수행하게 되죠~~
그만큼 Django는 자기가 데이터 관리의 주체가 되려 모든 노력을 다한다, 이런 상황에서 Django ORM을 사용하지 않고 직접적으로 DB에 접근하여 값을 추가하면 상당히 골치 아픈 문제가 발생하게 되더라고요....
즉, Django를 사용한다면 Default 옵션을 제거한다는 점을 항상 인지해야 할 것 같아요~! 무야호~~
2-5) 신기한 JOIN 쿼리
Join을 하는 방식이 Spring Data JPA와는 다르게 참조모델의 필드를 지정하는 방식을 사용합니다.
글보다는 코드로 살펴볼까요?
product_queryset = Product.objects.filter(store__name__contaions="shine마켓")
생성되는 SQL
SELECT "product", "id", "product", "name"
FROM product INNER JOIN store
ON (product.store_id = store.id)
WHERE store.name LIKE %shine%;{참조 모델명}__{필드명}={원하는 검색 키워드}와 같이 사용하여 JOIN문을 수행하게 되는데...
개인적으로 Spring Data JPA의 QueryMethod도 그렇고, 위와 같은 방식도 그렇고 메서드 이름으로 쿼리문 만드는 방식을 별로 좋아하지는 않아요.
진짜 단순한 CRUD 정도만 사용하여하는 편 이거든요. 예를 들어 create, delete를 주로 사용하는 편이죠~
그 외의 쿼리는 QueryDSL과 같이 빌더를 사용하여 쿼리릴 만드는 것을 선호하는 편입니다.
(아니 그럼 "뭐 하러 ORM 쓰냐?"라고 할 수 있는데, ORM을 쓰는 이유는 단순히 객체 영속화를 편하게 할 수 있다는 점만이 아닙니다. ORM에는 여러 장점들이 녹아있는 기술이거든요! 예를 들어 1차 캐시, 2차 캐시, 영속성 컨텍스트, 등등 여러 장점이 있기에 사용하기에 단순히 QueryMethod를 싫어한다 하여 ORM자체를 사용 안 할 이유는 없다고 저는 생각합니다!!)
3. 느낀 점
이 외에도 사실 여러 Django의 신기하면서도 자잘한 특징들이 3개 정도 더 있었는데, 일단 확실하게 체감되는 내용을 위주로 작성하였습니다!
개인적으로, 이번 DRF를 공부하면서 사실 엄청 설래이는 기간이었거든요!
그동안 Spring만 사용하면서 어느 정도 기술에 익숙해져 있었기 때문에 "기술에 대한 설레는 마음가짐"을 느끼지 못하고 있었던 것이 사실이었기에....
하지만 이번 POC 과정을 통하여 Django를 재미있게 공부해 볼 수 있었으며, 엔지니어로써 설래이는 그 감정을 느낄 수 있어 매우 행복했달까요?
어떠한 기술이 개발자를 불편하게 만들기 위해 나오는 경우는 거의 없다고 생각합니다.
DRF 또한 Django에서 기조에 불편했던 점을 개선하여 REST Api를 편리하게 만들어주기 위해 지원된 도구임이 분명하거든요!
또한 이를 사용하면 생산성이 극대화되는 점을 나 또한 직접 경험해 볼 수 있어서 매우 좋았다고 생각합니다(?)
아.. 근데 이게 또 정말 사용하기에 편했냐?라고 물어본다면 음..... 그냥 FBV 방식이 훨씬 생산성이 더 좋은 것 같은데........
이쯤 유명한 격언이 하나 떠오르네요...
No Silver Bullet - Essence and Accident in Software Engineering
은총알은 없다 - 소프트웨어 공학에 있어 본질과 부수성

어떤 기술이든 장점과 단점이 모두 존재하기 마련이다. DRF 또한 적절한 상황에 사용하면 매우 탁월한 기술이 되어줄 수 있다 생각합니다.
개발자는 도구가 무엇인지 고려하기보다는, "문제를 해결할 수 있는지?"가 더 중요하다 생각하거든요!
이번 기간을 통해 나 스스로 한 단계 더 발전하는 경험을 할 수 있었으며, 더 넓은 시야를 갖게 되어 정말 즐거웠던 시간이었습니다!!
'BackEnd > 기타' 카테고리의 다른 글
| 계층형 아키텍처는 왜 데이터베이스 중심의 설계를 유도할까? (0) | 2024.01.25 |
|---|---|
| [IntelliJ] IntelliJ 에서 DSM을 이용하여 패키지 간 의존성 확인하기 (0) | 2022.08.01 |
댓글