
1. 문제가 되는 상황
테스트 서버가 새벽에 지속적으로 다운되는 현상이 발생하고 있다.... 로그만으로는 정확한 원인을 파악하기 힘들어... prometheus와 grafana를 통해 메트릭을 정확하게 측정하게 되었다.
총 3부분을 살펴보았다.
1) CPU 사용량
2) JVM 메모리 사용량 초과
3) 커넥션 풀 고갈
4) vmstat 확인
2. 모니터링
2 - 1) CPU 사용량?
우선 다음 지표를 살펴보자
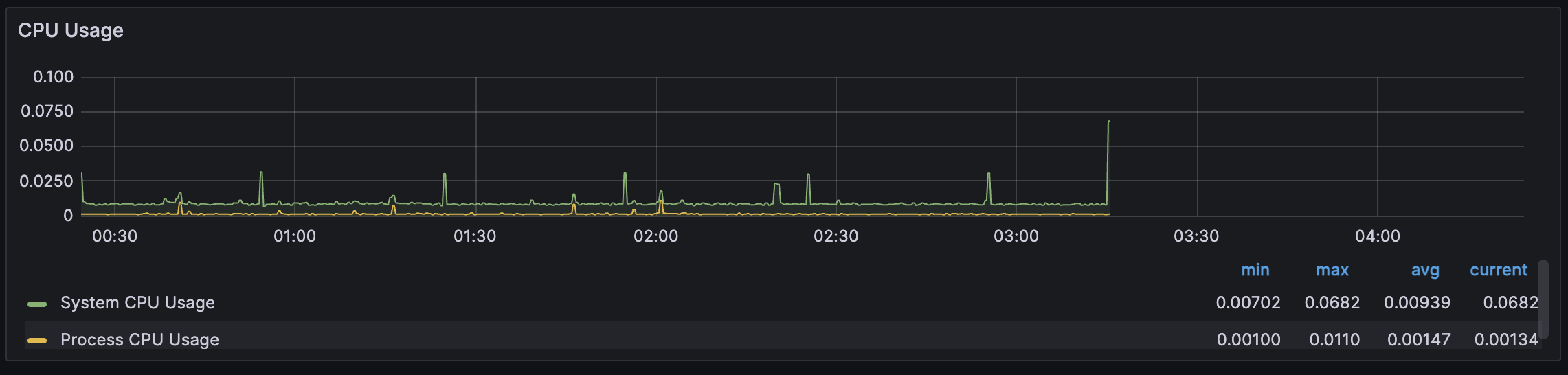
정기적으로 새벽 2기에 작동하는 작업이 있기 때문에 0시 ~ 4시 의 지점을 살펴보게 되었다.
다행히 터진시각 또한 대략 3시 15분경인데, 그래프에 보이듯 System CPU 사용량이 정상대비 증가하다 다운된 것 같다.
평균값이 0.00939인 상황에서 CPU 사용량이 0.0682까지,
약 7배가량 CPU 사용량이 증가하였다.
하지만 이게 정말 CPU 사용량이 높아서 중지되었다고 보기는 어려운 수치인 것 같은데...
(2024-01-18 : 나중에 알게 되었지만 CPU가 아닌 메모리 문제였다)
하지만 다른 이유가 떠오르지 않았고, 일단 지표로 보이는 CPU 사용률을 토대로 미루어 보아, 마지막에 서버가 터진 이유가 CPU사용량이 급증해서 터진 것이라 판단하였다.

이전 24시간의 기록을 살펴봐도, 0.0418이 최대인데, 분명 어디선가 종료 직전에 CPU를 많이 사용한 것은 분명한 것 같다.
그럼 어떠한 이유로 CPU 사용량이 증가한 것일까? 이를 알아보자!
2 - 2) JVM 메모리 사용량 초과?
다음으로는 JVM의 heap 영역을 중심으로 살펴보게 되었다.

흠... 딱히?? max의 절반정도를 꾸준하게 사용 중인 상태인데, 문제 될 부분은 없다 여겨진다.
즉, 객체가 너무 많이 생성되거나, memory leak이 발생해서 발생하는 문제는 아니라 판단하게 되었다.
(2024-01-18 : 나중에 추가 조사로 알게 되었지만, 이 판단은 잘못된 판단이었다, 해당 메모리는 Heap영역만 고려한 부분이다.
전체 메모리는 더 많이 사용 중이었으며 OOM이 발생하고 있었다.) 다음 https://blogshine.tistory.com/687 글에서 이를 해결하였다.
2 - 3) Connection Pool 고갈?
그다음으로 살펴본 메트릭은 Connection Pool이 고갈되는지였다.

흠... 일단 요청이 너무 많아 connection pool 자체가 말라버리는 timeout은 단 한 번도 발생하지 않았다.
-> 즉 요청이 너무 많이 발생하는 문제는 아니라 판단하였다...
그럼 뭐가 문제있은 건데...
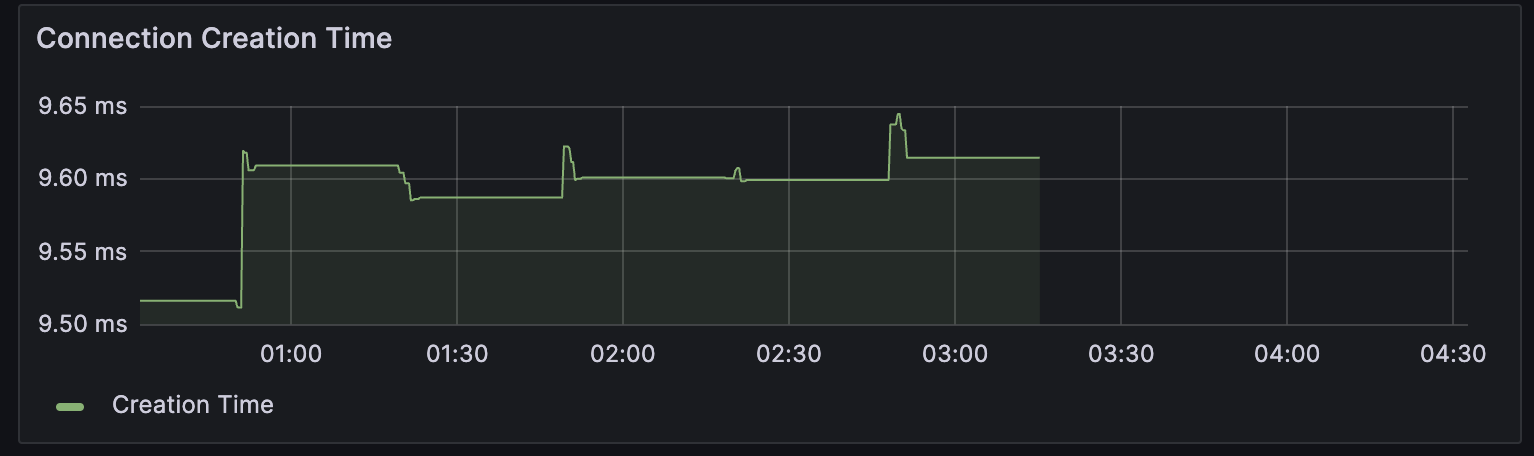
Connection 자체가 여러 개 만들어지는 상황에서... Connection 생성 시 간이 조금 늘어나는 것 같다.
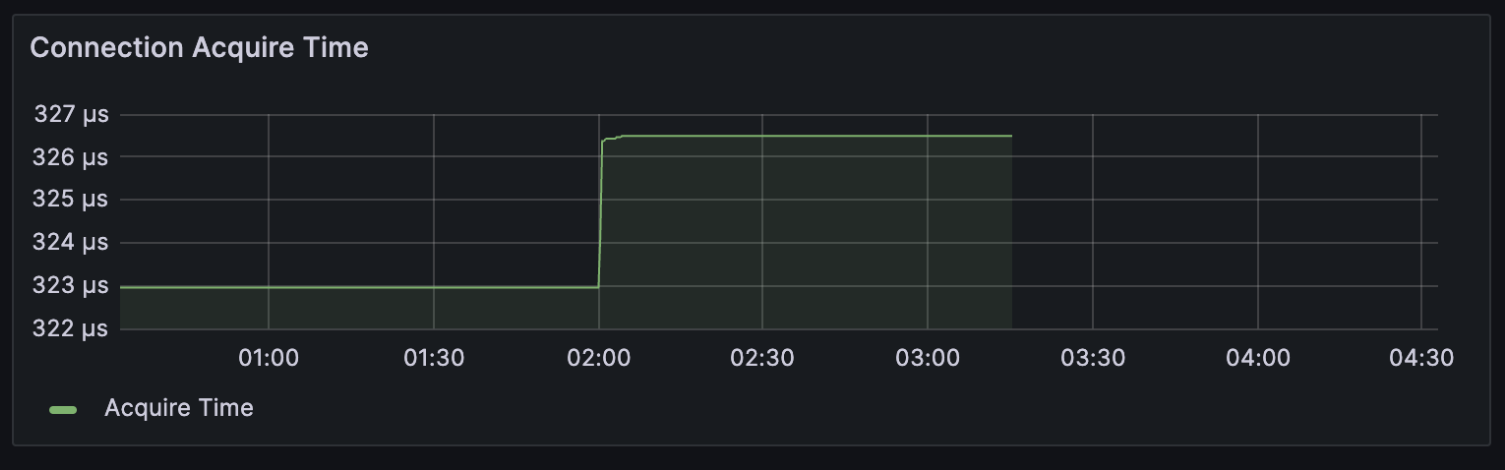
추가로 Connection Acquire Time을 살펴보니, 정확하게 2시부터 acquire time이 증가한다
1) 이는 2시에 시작하는 정규 작업에서 Connection들을 획득한 후
2) 해당 공지 page에서 응답이 없다면 최대 30초간 time out이 나기 전까지 대기하게 되고
3) 오랫동안 해당 connection을 들고 있기에 acquire time이 증가되었다 생각되었다.
종합해 보면!
CPU 사용량이 증가하고, Connection 획득 시간이 길어진다.
하지만 Connection Time out이 발생하는 것 은 아니다. (즉 요청이 많아서 터지는 것은 아닌 것 같다)
아마 공지를 스크랩 작업하는 I/O bound job 때문인 것 같다. (외부 요청 처리 시간 또한 지연되고 있다 보니... 학교 서버가 너무 느리다...)
추가적으로 리눅스 명령어인 vmstat 1을 통해 1초 단위로 상태를 확인해 봤는데, 실제로 b에 해당되는 작업량이 더 많았다.
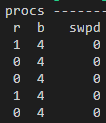
또한... 일단 코드 상에 문제는 정말 보이지 않기 때문에, 서버 인스턴스의 Scale Up을 적용해 보기로 했다.
특히 IO 연산량을 높이기 위해서 IOPS가 높은 인스턴스 유형으로 변경해 주도록 하였다.
이후 3일이 지난 오늘 다행히 아직까지 서버가 다운되고 있지 않고 정상 작동하고 있다.
며칠은 좀 더 지켜봐야 할 것 같지만, 아마도 해결된 것 같다?
(2024-01-18 : 이는 사실 메모리 자체가 늘어나 해결된 것이었다... https://blogshine.tistory.com/687 )
18일 진나 후 현제까지 종료되는 현상은 다행히 발생하지 않고 있다.
'BackEnd > 쿠링' 카테고리의 다른 글
| [쿠링] 사용자 인증의 시작부터 끝까지의 여정 (5) | 2023.10.07 |
|---|---|
| [쿠링] 효율적인 Log 관리를 위한 여정 - 1 (2) | 2023.08.27 |
| [쿠링] 홍보 부스 후기 (feat 건국대 일감호 축제) (3) | 2023.05.20 |
| [쿠링] 검색 쿼리에 Full Text Index 적용하기 (0) | 2023.05.11 |
| [쿠링] Multi thread를 활용한 공지 조회속도 개선 (feat 동기화) (5) | 2023.04.28 |
댓글