
1.4 케이스를 열고
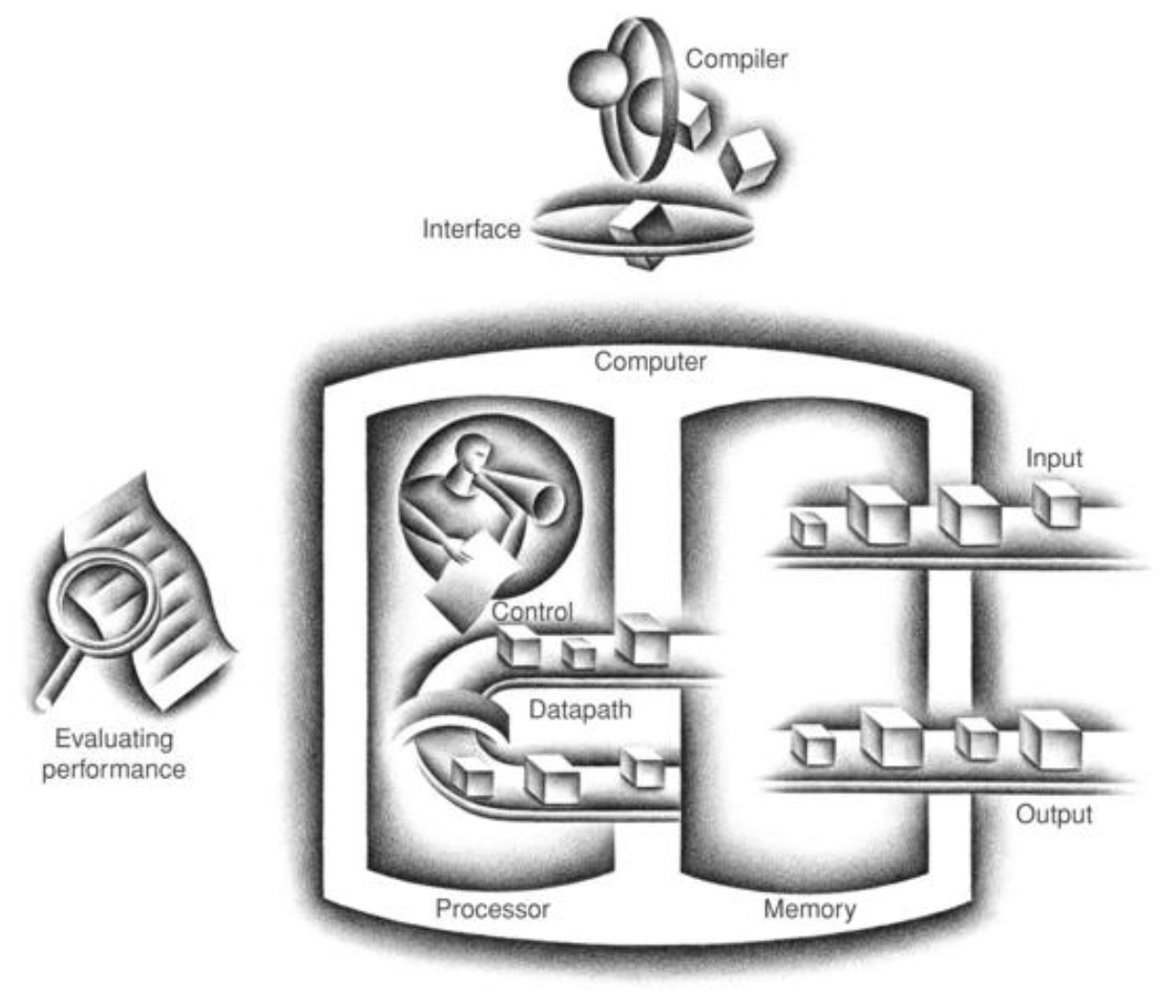
컴퓨터의 고전적 구성 요소 다섯가지는 다음과 같다.
1) 입력
2) 출력
3) 메모리
4) 데이터패스, datapath
5) 제어 유닛, control unit
이중 뒤의 2개를 합쳐서 프로세서라고 부르기도 한다.
위 그림은 컴퓨터의 표준 구성을 보여주는 그림이다. 이 구성은 하드웨어 기술과는 독립적이다.
1.4.1) 상자를 열고
다음 그림은 Apple iPhone Xs MAX 스마트폰의 내용물이다.

컴퓨터의 고전적인 5대 구성요소 중 입출력 장치의 비중이 큰것은 놀라울 일이 아니다.
입출력 장치로는 정전용량식 멀티터치 LCD 디스플레이 등이 있으며, 데이터패스, 제어 유닛, 메모리는 구성 요소 중의 작은 일부를 차지하고 있다.
다음 그림에는 직접회로(Intergrated circuit, IC) 또는 칩(chip)이라 불리는 장치들이 있는데, 이것들이 진보하는 기술을 이끌어 가는 원동력이다.

위 그림의 중앙부에 있는 A12 페키지에는 2.5GHz의 클럭으로 구동되는 2개의 큰 ARM 프로세서와 4개의 작은 ARM 프로세서가 있다.
프로세서는 프로그램의 지시대로 일을 하는 부분으로 보드 내에서 가장 역동적인 부분이다.
숫자를 더하고, 검사하고, 신호를 보내는 등의 작업을 프로세서가 수행한다. 일반적으로 CPU(central processor unit)이라는 용어로도 부른다.
다음 그림은 하드웨어 계층을 한단계 더 내려가서 마이크로 프로세서를 자세하게 보여준다.

프로세서는 논리적으로 데이터패스와 제어 유닛의 두 부분으로 구성된다. 각각은 근육과 두뇌에 비유할 수 있다.
데이터패스는 연산을 수행하고, 제어유닛은 명령어가 뜻하는 바에 따라 데이터패스, 메모리, 입출력 장치가 할 일을 지시한다.
메모리는 실행중인 프로그램과 프로그램이 필요로 하는 데이터를 기억한다. 메모리는 DRAM(dynamic random access memory)로 구성되어 있다.
프로세서 내부에는 또 다른 종류의 메모리가 있는데, 이것을 cache memory라고 한다.
캐시 메모리는 DRAM의 버퍼 역할을 하는 작고 빠른 메모리이다. 캐시는 SRAM이라는 메모리 기술을 이용한다.
SRAM은 DRAM보다 빠르지만 집적도가 낮아서 가격이 비싸다. SRAM과 DRAM은 메모리 계층 구조의 두 계층을 구성한다.
가장 중요한 추상화는 하드웨어와 최 하위 소프트웨어 간의 인터페이스 이다.
소프트웨어는 하드웨어와 어휘를 통해 통신을 한다. 어휘를 구성하는 단어들을 명령어라고 하고, 어휘 자체는 명령어 집합 구조(instruction set architecture)라고 한다.
명령어 집합 구조에는 제대로 작동하는 이진 기계어 프로그램 작성을 위해 프로그래머가 알아야 하는 것, ex) 명령어, 입출력 장치 등이 모두 포함된다.
입출력 작업, 메모리 할당 및 기타 저수준 시스템 기능의 세부 사항은 운영체제가 감추어서 응용 프로그래머가 이러한 세세한 부분을 걱정하지 않아도 되도록 해 주는 것이 일반적이다.
응용 프로그래머에게 제공되는 기본 명령어 집합과 운영체제 인터페이스를 합쳐서 ABI(application binary interface)라 한다.
이러한 추상화로 인하여 컴퓨터 설계자는 구조와 구조의 구현(implementation)을 분리해서 생각하게 된다.
1.4.2) 데이터의 안전한 저장소
컴퓨터 내부의 메모리는 휘발성 메모리 이다. 즉 전원이 꺼지면 모두 지워진다.
반면 DVD에 기록된 영화는 DVD플레이어의 전원을 꺼도 지워지지 않는다. DVD는 비휘발성 메모리 기술의 일종이기 때문이다.
전자를 메인 메모리, 후자를 보조기억장치 라고 한다.
1.4.3) 컴퓨터 간의 통신
아마도 네트워크 중에서 가장 널리 알려진 것은 이더넷(Ethernet)일 것 이다.
이더넷으로 연결할 수 있는 거리는 대략 1Km 정도이고, 초당 100GB를 전송할 수 있다. 이정도의 길이와 속도는 한 건물의 같은 층에 있는 컴퓨터들을 연결하는 데 유용하다. 그러므로 이더넷은 근거리 네트워크(LAN)의 일종이다.
라우팅 서비스와 보안을 제공하는 스위치를 사용하면 LAN들을 서로 연결할 수 있다. 원거리 네트워크(WAN)은 여러 대륙을 연결하여 WEB을 지원하고 있는 인터넷의 근간을 이룬다. 일반적으로 광섬유로 구성되며 통신회사에서 임대해준다.
1.5 프로세서와 메모리 생산 기술
▶ 트랜지스터(transistor)
한마디로 전기로 제어되는 on/off 스위치 이다. 직접회로는 수십, 수백개의 트랜지스터를 칩 하나에 집적시킨 것 이다.
더 나아가 수십만 내지 수백만개의 트랜지스터를 포함하고 있는 장치를 초대규모직접회로(VLSI)라고 부른다.
▶ 직접회로의 생성 과정
실리콘은 전기가 통하기는 하는데 썩 잘 통하는 편은 아니어서 반도체(semiconductor)라고 부른다.
특수한 화학적 처리를 거쳐 불순물을 첨가하면 실리콘의 작은 부분을 다음 세가지중 하나로 바꿀 수 있다.
- 전기의 양동체
- 전기 절연체
- 조건에 따라 도체가되기도 하고 절연체가 되기도 하는 물질
이중 트렌지스터는 마지막에 해당된다. VLSI는 수십억개의 도체, 절연체, 스위치를 작은 패키지 하나에 만들어 넣은 것 이다.
공정은 큰 소시지같이 생긴 실리콘 결정 괴(silicon crystal ingot)에서부터 시작된다.
이 덩어리를 0.1인치 이하의 두께로 얇게 잘라 웨이퍼(wafer)를 만든다.
이렇게 잘라진 웨이퍼는 화학 물질을 첨가하여 부분 부분을 트랜지스터, 도체, 절연체로 바꾸는 일련의 공정을 거치게 된다.
웨이퍼의 결함 때문에 완벽한 웨이퍼를 만드는것은 거의 불가능하다. 이를 대처하기 위해서 하나의 웨이퍼를 독립적인 컴포넌트 여러개로 나누는 것 이다. 이를 다이(die) 또는 칩 이라고 한다.
이렇게 여러 조각으로 나누면 웨이퍼에 결함이 생겼을 때 웨이퍼 전체를 버리는 대신 해당 다이만 버리면 된다.
이 개념은 수율(yield)로 계량화 할 수 있다. 수율은 웨이퍼상의 전체 다이중 정상 다이의 비율로 정해진다.
2020년 최첨단 공정은 7nm 공정인데 이것은 다이에서구현할 수 있는 최소 배선폭이 7nm라는 것을 의미한다.
결함이 없는 다이는 패키지의 입출력 핀과 연결하는데 이 과정을 본딩(bonding)이라고 한다.
1.6 성능
1.6.1) 처리량과 응답시간
개인 컴퓨터 사용자 입장에서는 응답시간(response time, 작업 개시애서 종료까지의 시간, 즉 실해시간)이 중요할 것 이다.
그러나 데이터센터 관리자에개는 처리량(throughput, 일정 시간동안 처리하는 작업의 양), 혹은 대역폭(bandwidth)이 더 중요하다.
그러므로 응답시간이 더 중요한 개인 휴대용 기기와 처리량이 더 중요한 서버의 성능을 평가할때는 대부분 다른 응용 프로그램과 다른 성능 척도를 사용한다.
성능을 최대화 하기 위해서는 어떤 task의 응답시간 또는 실행시간을 최소화 해야 한다.
따라서 어떤 컴퓨터 X의 성능과 실행시간의 관계를 다음과 같이 정의할 수 있다.

그러므로 두 컴퓨터 X와 Y에 대해 X의 성능이 Y의 성능보다 좋다면, 실행시간Y > 실행시간X가 된다.
1.6.2) 성능의 측정
실행시간은 프로그램을 처리하는데 걸린 시간을 초단위로 표시한 것 이다.
그러나 시간은 우리가 재는 방법에 따라 여러 가지로 정의할 수 있다. 제일 쉽게 생각할 수 있는 것은 vall-clock time, response time, elapsed time이라 부르는 것 이다.
이것은 한 작업을 끝내는 데 필요한 전체 시간을 뜻하는 것으로 디스크 접근, 메모리 접근, 입출력 작업, 운영체제 오버해드 등 모든 시간을 더한 것 이다.
이와 달리 순수하게 이 프로그램을 실행하기 위해 소비한 시간을 계산할 필요가 있다. 이를 CPU 실행 시간(CPU execution time)이라 부른다.
CPU 시간은
1) 실제로 사용자 프로그램 실행에 소요된 사용자 CPU 시간(user CPU time)
2) OS가 이 프로그램을 위한 작업을 수행하기 위해 소비한 시스템 CPU 시간(system CPU time)으로 다시 나뉜다.
일반 사용자와 달리, 컴퓨터 설계자는 하드웨어가 기본 함수를 얼마나 빨리 처리할 수 있는지와 관련된 성능 척도를 필요로 한다.
거의 모든 컴퓨터는 하드웨어 이벤트가 발생하는 시점을 결정하는 clock을 이용하여 만들어진다.
이 clock의 시간 간격을 clock cycle(또는, 틱, 클럭 틱, 클럭, 사이클)이라고 부른다.

클럭 주기(clock period)는 한 클럭 사이클에 걸리는 시간(예를 들면 250picosecond, 즉 250ps)이나 클럭 속도(예를 들면 4GHz)로 표시한다. 클럭 속도는 클럭 주기의 역수이다.
1.6.3) CPU 성능과 성능 인자
CPU의 성능만 고민해보면, 가장 기본적인 척도인 클럭 사이클 수와 클럭 사이클 시간으로 CPU 시간을 표시하면 다음과 같다.

클럭 속도와 사이클 시간은 역수 관계 이므로

위 공식을 보면, 클럭 사이클의 길이를 줄이거나 프로그램 실행에 필요한 클럭 사이클 수를 줄이면 성능을 개선할 수 있음을 알 수 있다.
이 둘중 하나를 감소시키면, 다른 하나가 증가하는 경우가 자주 발생한다.
1.6.4) 명령어 성능
앞의 예에서 사용한 수식에는 프로그램 수행에 필요한 명령어 개수에 관한 사항이 포함되어 있지 않다.
따라서 실행시간을 (실행 명령어 수 x 명령어의 평균 실행시간) 으로 계산할수도 있다. 그러므로 프로그램 실행에 필요한 클럭 사이클 수는 다음과 같다.ㅉㅉㅉㅉ
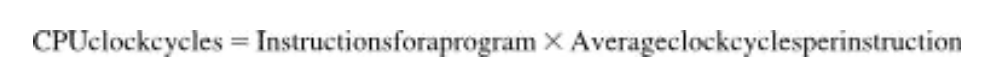
명령어당 클럭 사이클 수(clock cycles per instruction)은 CPI라고 줄여서 자주 사용한다.
명령어마다 실행시간이 다르므로 CPI는 프로그램이 실행한 모든 명령어에 대한 평균값을 사용한다. 명령어 집합 구조가 같으면 프로그램에 필요한 명령어 수가 같으므로, CPI는 서로 다른 구현을 비교하는 한 가지 기준이 될 수 이다.
1.6.5) 고전적인 CPU 성능식
성능식을 명령어 개수, CPI, 클럭 사이클 시간 으로 표시해보자.

클럭속도는 사이클 시간은 역수이므로,

그러면 성능식의 3가지 인자값은 어떻게 구할까?
CPU 실행시간은 실제 프로그램을 실행시켜 얻을 수 있고, 클럭 사이클 시간은 보통 컴퓨터의 하드웨어 매뉴얼에 기록되어 있다.
그러나 명령어 개수와 CPI는 구하기 조금 어렵다.
물론 속도와 CPU 실행시간을 알 때, 명령어 개수나 CPI중 하나를 알면 다른 하나는 계산으로 구할 수 있다.
CPI는 명령어 배합(instruction mix)에 따라 달라지므로 클럭 속도가 같더라도 명령어 개수와 CPI는 반드시 비교해야 한다.
▶ 코드의 비교
어떤 컴파일러 설계자가 가은 상위 수준 언어 문장에 대해 생성된 두 가지 코드 1과 2중 하나를 선택하려 한다.
다음과 같은 정보를 하드웨어 설계자로부터 받았다.

1) 어떤 코드가 더 많은 명령어를 실행하는가?
코드 1번은 5개의 명령어를 실행하고, 코드 2번은 6개의 명령어를 실행한다.
그러므로 코드 2가 더 많은 명렁어를 실행한다.
2) 어떤 것이 더 빠른가?
명령어의 개수와 CPI를 사용하여 CPU 클럭 사이클 수를 계산하는 다음 공식을 이용하면 각각의 코드에 대하여 클럭 사이클 수를 계산할 수 있다.

CPU 클럭 사이클 수1 = (2 * 1) + (1 * 2) + (2 * 3) = 10 사이클
CPU 클럭 사이클 수2 = (4 * 1) + (1 * 2) + (1 * 3) = 9 사이클
그러므로 코드2가 비록 명렁어는 하나 더 수행하지만, 실행 속도는 더 빠르다.
3) 각 코드의 CPI는 얼마인가?
코드 2의 경우 필요한 클럭 사이클 수는 적으면서 명렁어는 더 많이 실행하므로 CPI가 낮다.
CPI는 다음과 같이 구할 수 있다.

1.7 전력 장벽
오늘날의 문제는 전압을 더 낮추면 트랜지스터 누설 전류가 너무 커진다는 것 이다.
서버 칩에서 현재 이미 40%의 전력이 누설 전류에 의해 소모되고 이다. 트랜지스터 누설이 더 증가한다면 공정 전체가 제어 불가능한 상태가 될 것 이다.

1.8 단일 프로세서에서 멀티프로세서로의 변화
다음 그림은 아미크로프로세서의 프로그램 응다비간 개선 추세를 보여준다. 개선 속도가 2002년부터 매년 1.5배에서 1.03배로 둔화되었다

단인 프로세서 대신, 모든 데스크톱과 서버는 2006년 부터 여러개의 프로세서를 집적한 마이크로프로세서를 생산하였는데, 이는 응답 시간보다는 처리량 개선에 효과가 더 있었다.
일반적으로 processor를 core라 부르고, micro processor를 multicore processor라고 부른다.
▶ 하드웨어 소프트웨어 인터페이스
병렬성은 컴퓨팅의 성능에 늘 중대한 역할을 하였으나 대개 드러나지 않고 숨어 있다.
파이프라이닝은 명렁어의 실행을 중첩시켜서 프로그램을 빠르게 실행시키는 훌륭한 기술로, 명렁어 수준 병렬성의 한 예 이다.
파이프라이닝 에서는 하드웨어의 병렬적인 특성이 드러나지 않아서 프로그래머와 컴파일러는 하드웨어가 명령어를 순차적으로 실행시키는 것으로 여길 수 있다.
1.9 오류 및 함정
▶ 함정: 컴퓨터의 한 부분만 개선하고 그 개선된 양에 비례해서 전체 성능이 좋아지리라고 기대하는 것.
▶ 함정: 이용률이 낮은 컴퓨터는 전력 소모가 적다.
▶ 오류: 성능에 초점을 둔 설계와 에너지 효율에 초점을 둔 설계는 서로 무관한다.
▶ 함정: 성능식의 일부분을 성능의 척도로 사용하는 것
실행시간 대신에 쓸 수 있는 성능 척도 중 하나로 MIPS(million instructions per second)가 있다.
이는 프로그램의 실행 속도를 백만 개의 명령어 단위로 나타내는 척도이다.
MIPS는 실행한 명령어 개수를 (실행시간 * 10^6)으로 나누어 계산한다.

MIPS는 명령어 실행 속도이므로 실행시간의 역수로 성능을 표시한다. 따라서 빠른 컴퓨터일수록 높은 MIPS값을 갖는다.
'CS > Computer Organization Design (2023-1)' 카테고리의 다른 글
| [컴퓨터 구조] 4. 프로세서 (0) | 2023.06.16 |
|---|---|
| [컴퓨터 구조] 3. 컴퓨터 연산 (1) | 2023.05.09 |
| [컴퓨터 구조] 2. 명령어: 컴퓨터 언어 (0) | 2023.04.17 |
댓글