데이터베이스 시스템 7판을 읽으며 간략하게나마 정리하는 글입니다.

1. 함수와 프로시저
프로시저와 함수는 "비즈니스 로직, 규칙"이 데이터베이스에 저장되고 SQL 구문이 실행되도록 해 준다.
이러한 비즈니스 로직을 데이터베이스 외부보다는 , 내부에 저장하면 장점을 가진다.
예를 들면, 응용프로그램의 변경없이 비즈니스 규칙이 변경되는 경우에 단지 그 변경만 허용할 수 있다.
응용프로그램 코드가 데이터베이스의 릴레이션에 직접적으로 변경하는 대신에 프로시저를 호출할 수도 있다.
1 - 1) SQL 함수 및 프로시저의 선언과 호출
학과 이름을 받아서, 그 학과 교수의 수를 반환하는 함수를 생각해보자!
예를 들어 다음과 같이 12명 이상의 교수를 가진 모든 학과의 이름과 예산을 반환하는 SQL문은 다음과 같을 것입니다.
select dept_name, budget
from department
where dept_count(dept_name) > 12;위에서 사용한 dept_count 함수는 프로시저로 다음과 같이 나타낼 수 있습니다.
create procedure dept_count (in dept_name varchar(20), out d_count integer)
begin
select count(*) into d_count
from instructor
where instructor.dept_name = dept_count.dept_name
endin, out은 각각 입력받을 값과 반환될 값이 저장될 매개변수를 나타낸다.
프로시저는 SQL 프로시저나 내장 SQL로부터 호출 구문을 통해 호출될 수 있다.
declare d_count interger;
call dept_count('Physics', d_count);
질의에서 복잡한 사용자 정의 함수를 호출할 때 많은 데이터베이스 시스템에서 성능상의 문제가 발생한다.
따라서 사용자 정의 함수는 성능을 고려해야 한다.
SQL 표준은 table function이라 불리는 테이블 자체를 반환하는 함수를 지원한다.
create function instructor_of(dept_name varchar(20))
return table (
ID varchar(5),
name varchar(20),
dept_name varchar(20),
salary numeric (8, 2)
)
return table (
select ID, name, dept_name, salary
from instructor
where instructor.dept_name = instructor_of.dept_name
);이 함수는 특정한 학과의 모든 교수를 포함하는 테이블을 반환한다.
함수의 매개변수는 함수 이름의 접두사(instructor_of.dept_name)로 참조하는 것을 주의하자.
함수는 다음과 같이 사용하면 된다.
select *
from table(instructor_of('Finance'));위 질의는 'Finance'에 속하는 모든 교수를 반환합니다.
위와 같이 단순한 경우에는 테이블 함수를 작성하지 않고 바로 이러한 질의를 작성하는 것이 쉽습니다.
하지만 일반적으로 테이블 함수는 매개변수를 허용하여 뷰를 정의하는 매개변수화된 뷰 로 생각할 수 있습니다.
SQL은 매개변수의 수가 다르면 같은 이름을 가진 여러 개의 프로시저를 허용한다.
즉, 이름과 매개변수의 수가 프로시저를 판단하는 데 사용된다.
또 매개변수의 수가 같더라도 적어도 하나의 타입이 다르면 같은 이름을 가진 함수를 사용할 수 있습니다.
https://gdtbgl93.tistory.com/149
[PL/SQL] 함수와 프로시저
PL/SQL의 대표적인 부 프로그램에는 함수(Function)과 프로시져(Procedure)가 있다. 함수(Function) 함수 생성 CREATE OR REPLACE FUNCTION 함수 이름 (매개변수1, 매개변수2....) RETURN 데이터 타입; IS[AS]..
gdtbgl93.tistory.com
언어마다 함수와 프로시저의 구문이 너무나 다르다. 위 글에서 Oracle에 대한 설명을 볼 수 있다.
1 - 2) 프로시저와 함수를 위한 언어 구문
SQL은 범용 프로그래밍 언어의 거의 같은 기능을 가진 다양한 구조를 지원한다.
이러한 구조를 다루는 SQL 표준의 일부를 영구 저장 모듈(Persistent Storage Module, PSM)이라 부른다.
변수는 declare를 통해 선언되고, 값의 할당은 set을 통해 수행된다.
복합문은 begin ... end의 형태를 가진다.
즉, begin ... end 사이에 다수의 SQL 구문을 포함할 수 있다.
begin ... end의 형태의 중문은 그 안에서 수행되는 모든 문장이 단일 트랜잭션으로 수행되도록 한다.
▶ while, repeat문
while boolean expression do
sequence of statements;
end while
repeat
sequence of statements;
until boolean expression
end repeat
▶ for 반복문
declare n interger default 0;
for r as
select budget from department
where dept_name = 'Music'
do
set n = n - r.budget
end for질의 결과를 한 번에 한 개의 행으로 for 반복문의 변수(r)로 가져온다.
추가로 leave문은 반복문을 빠져나갈 때 사용되며, iterate는 나머지 구문을 건너뛰어 반복문의 시작에서 다음 튜플로부터 시작한다.
▶ if-then-else 구문
다음과 같이 사용한다.
if boolean expression
then statement or compound statement
elseif boolean expression
then statement or compound statement
else statement or compound statement
end if
▶ 예외 처리 handler
코드는 다음과 같다.
declare out_of_classroom_seats condition
declare exit handler for out_of_classroom_seats
begin
sequence of statements
endbegin과 end 사이의 구문은 신호 out_of_classroom_seats를 실행하는 데 예외 처리를 발생시킨다.
예외 처리 핸들러는 이러한 조건이 방생하면 begin end 구문을 닫고 빠져나가는 행동을 취한다.
2. 트리거
트리거(trigger)는 데이터베이스에서 발생하는 특정 사건에 대한 반응으로 시스템이 자동으로 수행하는 구문이다.
트리거를 정의하기 위해서는 다음의 두 가지를 명시해야 한다.
- 트리거가 실행될 시점을 명시해야 한다. 이것은 트리거가 검사 되어야 하는 사건이나 만족되어야 하는 조건이다. 트리거가 실행될 때 수행되어야 할 동작을 명시해야 한다.
- 트리거가 실행될 때 수행되어야 할 동작을 명시해야 한다.
2 - 1) 트리거의 필요성
트리거는 SQL의 제약조건 방법을 통해 명세할 수 없는 무결성 제약 조건을 구현하기 위해 사용될 수 있다.
또한 트리거는 어떤 조건을 만족시켰을 때 알려주거나 작업을 처리하기 좋다.
예를 들어 takes 릴레이션에 튜플 하나가 삽입될 때마다 학생의 전체 이수 학점을 다시 계산해서 student 릴레이션에 있는 튜플을 갱신하는 트리거를 만들 수 있다.
트리거는 데이터베이스 외부에 대한 갱신을 수행할 수가 없다.
예를 들어 제고가 최소 재고량과 현재 재고량을 비교하여 현재 재고량이 최소 재고량 이하인 경우 새로운 주문을 orders 릴레이션에 추가할 수는 있다.
하지만 직접적으로 주문을 하는 데 사용할 수는 없다. DB에만 추가될 뿐이다.
3. 재귀 질의

위와 같은 prereq 릴레이션의 인스턴스가 있다고 해보자!
이제 어떤 과목의 직접, 간접적인 선행 과목을 찾고 싶다 하자.
다시 말해 CS-347에 대한 직접적인 선행 과목이나 CS-347의 선행 과목의 선행 과목을 찾고 싶은 것이다.
prereq 릴레이션의 이행 폐포(transitive closure)는 pre가 직접, 간접적으로 cid의 선행 과목인 모든 쌍(cid, pre)을 포함하는 릴레이션이다.
이행 폐포란 어떤 정점 A에서 C로 가는 직접 경로는 없고, 우회경로가 있을 때 A->C로의 간선을 연결한 그래프를 의미한다.
예를 들면 다음 오른쪽 그림과 같다.

3 - 1) 반복을 통한 이행 폐포
위에서 말한 질의를 작성하는 한 가지 방법은 반복문을 사용하는 것이다.
우선 CS-347의 직접적인 선행 과목을 찾는다, 이후 첫번째 집합에 있는 과목의 선행과목을 찾는다.
이러한 반복은 어떠한 과목도 찾을 수 없을 때까지 반복한다.
이러한 작업을 하는 findAllPrereqs(cid) 함수를 살펴보자.

이 프로시저는 3개의 임시 테이블을 사용한다.
- c_prereq : 반환하는 튜플들의 집합을 저장한다.
- new_c_prereq : 이전의 반복에서 발견된 과목을 저장한다.
- temp : 과목들의 집합을 유지하기 위한 임시 저장소로서 사용된다.
SQL은 create temporary table 명령을 사용해서 임시 테이블을 생성할 수 있다.
임시 테이블은 질의를 수행하는 트랜잭션 동안에만 존재하고 트랜잭션이 끝날 때 삭제된다.
프로시저는 과목 cid의 직접적인 선행 과목을 repeat 반복이 시작되기 전에 new_c_prereq에 삽입한다.
repeat 반복은 먼저 new_c_prereq의 모든 과목을 c_prereq에 추가한다.
다음으로는 cid의 선행 과목으로 이미 발견된 과목을 제외한 new_c_prereq에 있는 모든 과목의 선행 과목을 계산하고 이 계산된 것을 임시 테이블인 temp에 저장한다.
마지막으로 temp의 내용으로 new_c_prereq의 내용을 교체한다. repeat 반복은 더 이상 새로운 선행 과목을 찾을 수 없을 때 종료된다.
다음 그림은 CS-347이라는 과목에 대해 프로시저가 호출되었을 때 각각의 반복에 의해 발견된 선행 과목을 보여준다.

3 - 2) SQL에서 재귀
반복을 통한 이행 폐포를 명시하는 것은 다소 불편하다.
대안적인 방법으로는 재귀적 뷰 정의를 이용하는 방법이 있는 데 사용하기 더 쉽다.
CS-347에 대한 선행 과목의 집합을 CS-347에 대한 선행 과목에 대한 선행 과목의 집합으로 재귀적으로 정의하기 때문이다.
SQL 표준은 뷰를 표현할 때 with recursive 절을 사용하여 재귀의 제한적인 형태를 제공한다.
예를 들어 이행 폐포를 표현하기 위해 재귀 질의가 사용될 수 있다.
예를 들면, pre가 직접 혹은 간접적으로 과목 cid에 대한 선행 과목이 되는 모든 쌍을 재귀적 SQl뷰를 사용하여 찾을 수 있다.

어떤 재귀적 뷰도 반드시 두 개의 하위 질의의 합으로서 정의되어야 한다.
위 예제에서 기본 질의는 prereq의 선택 연산인 반면, 재귀 질의는 prereq와 rec_prereq의 조인을 계산한다.
재귀적 뷰의 의미는 다음과 같다.
우선 기본 질의를 계산하고 결과로 생기는 모든 튜플을 뷰 릴레이션 rec_prereq에 추가한다.
그다음 뷰 릴레이션의 현재 내용을 사용하여 재귀 질의를 계산한 후 모든 결과 튜플을 뷰 릴레이션에 다시 추가한다.
위 과정을 뷰 릴레이션에 추가되는 튜플이 없을 때까지 반복한다.
결과로 생성되는 뷰 릴레이션 인스턴스는 재귀적 뷰 정의의 고정점(fixed point)라 불린다.
재귀적 뷰에서 재귀 질의에 대한 제한이 있을 수 있다.
특히, 단조(monotonic) 로워야 한다.
즉, v1이 v2의 상위 집합이면 뷰 릴레이션 인스턴스 v1에 대한 결과가 뷰 릴레이션 인스턴스 v2의 결과의 상위 집합이어야 한다.
특별히 재귀 질의에서는
재귀적 뷰에서 집계 함수, 재귀적 뷰를 사용하는 하위 질의에서 not exists와 같은 생성자를 사용하면 복합해진다.
따라서 사용하지 말아야 한다.
4. 고급 집계 기능
몇 가지 고급 집계 기능에 대하여 알아보자.
4 - 1) 윈도우
윈도우 질의는 튜플의 범위에 대한 집계 함수를 계산한다.
예를 들어, 시간의 고정된 범위에 대한 집계를 계산하는 데 유용하다. 여기서 시간의 범위가 윈도우(window)라고 불린다.
윈도우 함수에는 OVER 문구가 키워드로 필수 포함된다.
매년 학생들이 수강한 학점 총합을 보여주는 tot_credits(year, num_credits) 뷰가 있다고 하자.
이 릴레이션이 매년 기껏해야 하나의 튜플만 가질 수 있다는 점을 명심하자.

위 쿼리는 명시된 정렬 순서로 3개의 이전 튜플에 대한 평균을 계산한다.
따라서 2019를 기준으로 2018, 2017까지 3개의 rows에 대한 값들의 평균을 구하게 된다.
tot_credits의 가장 빠른 해에 평균은 그해 자체이고, 그다음 해는 2년 치에 대한 평균이다.
https://widecheon.tistory.com/379
[퍼옴] 윈도우 함수 (UNBOUNDED PRECEDING / FOLLOWING / CURRENT)
윈도우 함수 [출처] 윈도우 함수 (UNBOUNDED PRECEDING / FOLLOWING / CURRENT)|작성자 Kyrandes 분석함수중에서 윈도우절(WINDOW절)을 사용할수 있는 함수를 윈도우함수라고 한다. 고로 분석함수중에서 일부만
widecheon.tistory.com
이번에는 고정된 수의 튜플 대신 모든 해로 구성된 윈도를 가정해 보자.
이것은 모든 해의 수가 고정되어 있지 않음을 의미한다.
모든 해에 대한 전체 학점 평균을 얻기 위해 다음을 작성한다.
select your, avg(num_credits)
over (order by year rows unbounded preceding)
as avg_total_credits
from tot_credits;preceding 대신 following 키워드가 사용 가능하며,
UNBOUNDED PRECEDING : 윈도우의 시작 위치가 첫번째 ROW
UNBOUNDED FOLLOWING : 윈도우의 마지막 위치가 마지막 ROW
비슷하게 현재 튜플의 앞에 윈도우 시작지점을 설정하고, 뒤에 끝을 명시할 수 있다.
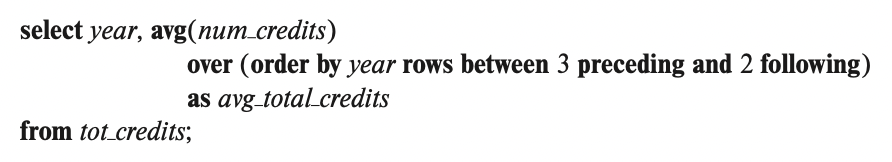
마지막으로 특정 학과에서 수강한 학점 전체를 보여주는 tot_credits_dept(dept_name, year, num_credits) 뷰를 통해 각 학과에 대한 학점 데이터를 가지고 있다고 가정해보자.
dept_name으로 분할된 각각의 학과를 다루는 윈도우 질의를 다음과 같이 작성할 수 있다.

row 대신 range 키워드를 사용하는 것은 윈도우 질의가 특정 개수의 튜플이 아니라 특정한 값을 갖는 모든 튜플을 대상으로 한다는 것을 의미한다.
rows current row는 정확히 하나의 튜플을 의미하지만, range current row는 sort속성의 값이 현재 튜플의 해당값과 같은 모든 튜플을 의미한다.
다만, range는 모든 데이터베이스 시스템에 완벽히 구현되어 있지는 않다.
4 - 2) 피벗팅
다음과 같은 스키마를 가지는 sales 릴레이션이 있다고 해보자.
sales(item_name, color, clothes_size, quantity)item_name은 (skirt, dress, shirt, pants)중 하나, color은 (dark, pastel, white)중 하나, clothes_size는 (small, medium, large)중 하나의 값을 각각 가지고, quantity는 주어진 품목의 전체 수를 나타내는 정수 값이다.
이는 다음과 같다.
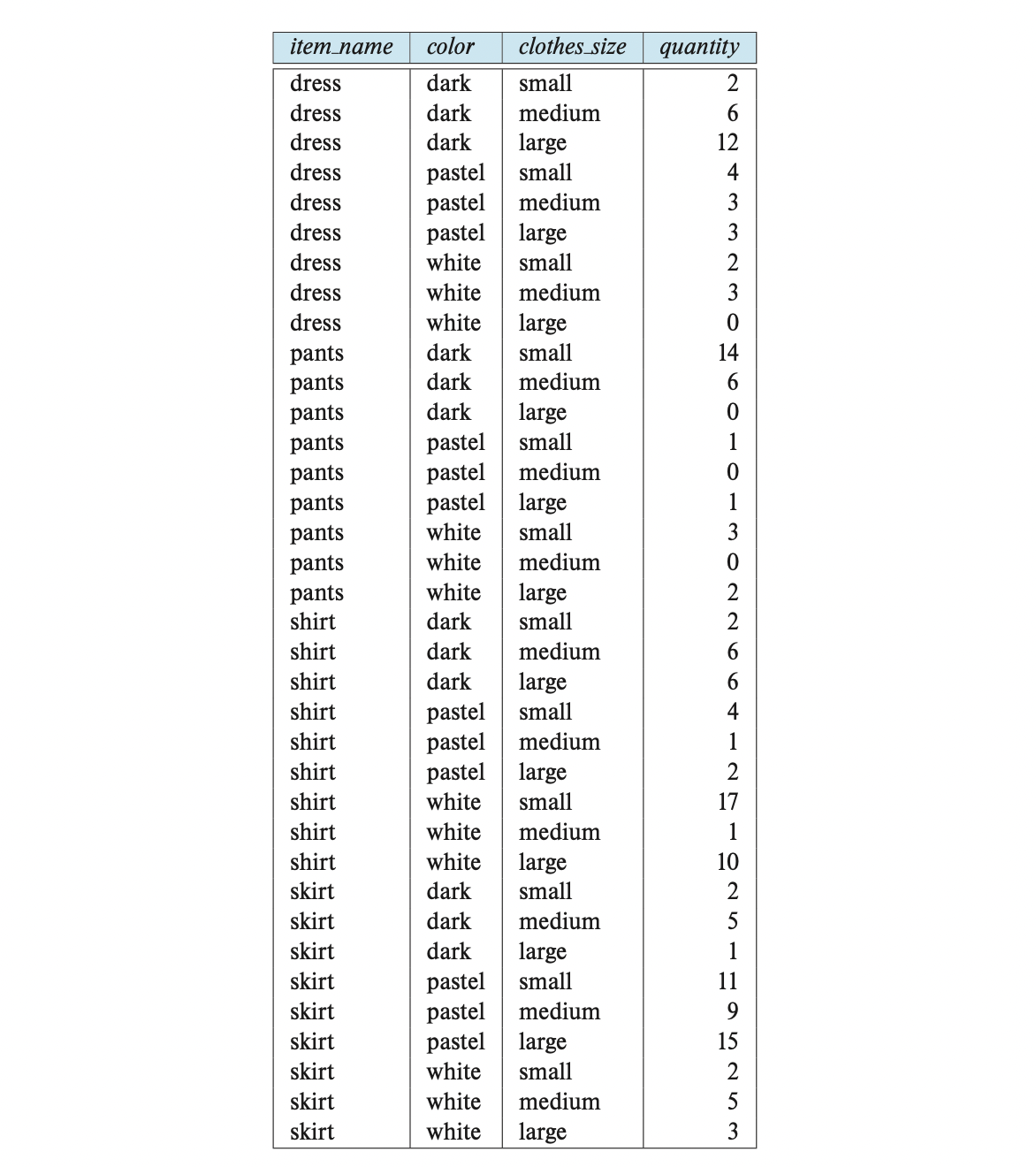
이러한 데이터를 바라보는 또 다른 방법을 제공한다.
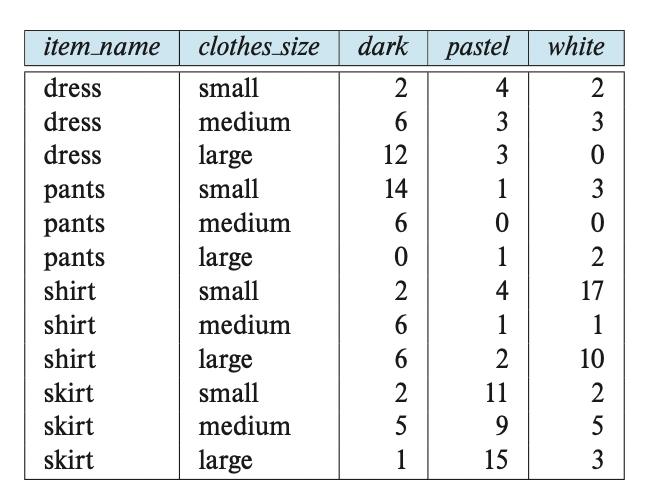

속성 color의 값 "dark", "pastel", "white"는 속성의 이름이 되었다.
위 릴레이션은 cross-tabulation 또는 pivot-table의 예이다.
일반적으로 cross-tabulation은 어떤 릴레이션 R의 특정 속성의 값이 속성이 되는 테이블이라 할 수 있다.
이러한 속성을 pivot 속성이라 부른다.
pivot절 안에 있는 for 절은 1) 피벗의 속성과 2) 피벗 결과에 속성 이름으로 출현해야 하는 속성의 값이며
새로운 속성의 값을 계산하는 데 사용되는 집계 함수 sum을 명세한다는 것을 유의하라.
또한 주어진 cell에 영향을 미치는 튜플이 하나 이상이라면, pivot절 안에 집계 함수를 통해 해당 값들을 어떻게 처리해야 할지 명시해야 한다.
4 - 3) 롤업과 큐브
SQL은 cube와 rollup 연산을 사용하여 group by 연산자의 일반화를 제공한다.
cube와 rollup은 다수의 group by 질의가 단일 질의에서 수행되고 결과도 단일 릴레이션으로 반환되도록 해준다.
위 소매점의 스키마를 다시 살펴보자.
sales(item_name, color, clothes_size, quantity)group by를 통해 각 품목별 팔린 품목의 수 등을 찾을 수 있다.

만약 품목명과 색상에 의해 판매량을 나누고 싶다면 다음과 같이 작성할 수 있다.

SQL cube와 rollup 은 다수의 질의를 작성하는 대신 단일 질의를 사용해 다수의 집계 연산을 간략하게 할 수 있는 방법을 제공한다.
따라서 다음과 같이 작성할 수 있다.
왼쪽이 rollup을 사용한 방식이며, 오른쪽은 동일한 결과를 출력하는 union을 사용한 방식이다.


결과는 다음과 같다.

group by rollup(item_name, color)은 3개의 그룹을 생성한다.
{(item_name, color), (item_name), ()}여기서 ()는 빈 리스트를 의미한다.
rollup의 경우 앞에 나와 있는 속성(item_name), 그리고 두 개의 속성을 모두 포함하는 (item_name, color) 그룹이 만들어진다.
따라서 rollup절에 등장하는 순서에 따라 그룹이 달라질 수 있다.
cube 생성자는 cube 생성자 안에 나열된 속성들의 모든 부분집합으로 구성된 꽤 많은 수의 그룹을 생성한다.

위 질의는 다음과 같은 그룹을 생성한다.
{ (item_name, color, clothes_size), (item_name, color), (item_name, clothes_size),
(color, clothes_size), (item_name), (color), (clothes_size), () }다른 그룹의 결과로부터 공통의 스키마를 만들기 위해 rollup을 사용했듯, 결과에 있는 튜플들이 특정 그룹에 출현하지 않는 속성의 값을 null값을 사용하게 된다.
마지막으로 다수의 rollup과 cube 절을 단일 group by절 안에서 사용할 수 있다.
예를 들어 다음과 같은 질의가 있다.

각각 다음과 같이 집합이 생성된다.
rollup(item_name) => {(item_name), ()}
rollup(color, clothes_size) => {(color, clothes_size), (color), () }두 개의 카티션 곱으로 인하여 6개의 그룹이 생성된다.
{ (item name, color, clothes size), (item name, color), (item name),
(color, clothes size), (color), () }
데이터 분석가는 rollup, cube 연산에 의해 생성되는 null과 데이터베이스에 저장되는 일반적인 null을 구분하기를 원한다.
grouping() 함수는 만약 인자가 rollup, cube에 의해 생성된 null이라면 1을 반환하고, 아니라면 0을 반환한다.
따라서 다음과 같이 1로 반환될 때 "all"이라 명시해줄 수 있다.

'CS > DB (2022-1)' 카테고리의 다른 글
| [DB] 물리적 저장 장치 시스템 (0) | 2022.10.09 |
|---|---|
| [DB] E-R 모델을 사용한 데이터베이스 설계 (0) | 2022.10.06 |
| [DB] 중급 SQL - 2 (1) | 2022.09.30 |
| [DB] 중급 SQL - 1 (1) | 2022.09.29 |
| [DB] 관계형 모델 소개 (0) | 2022.09.26 |
댓글