데이터베이스 시스템 7판을 읽으며 간략하게나마 정리하는 글입니다.

이번 쳅터에서는 Join, View 정의, 트랜잭션, 무결성 제약 조건과 권한 허가에 대하여 알아보자.
1. Join 표현식
1 - 1) Natural Join
자연 조인 연산은 두 개의 릴레이션에 대해 수행되고, 하나의 릴레이션을 결과로 생성한다.
카티션 곱 같은 경우 선행 릴레이션의 각 튜플과 후행 릴레이션의 모든 튜플을 짝지어서 릴레이션을 생성하지만,
자연 조인은 두 릴레이션의 스키마에 나타나는 속성 값이 같은 튜플의 짝만 고려한다.
student natural join takes위 표현은 student와 takes의 공통 속성인 ID에 대하여 동일한 값을 가지는 짝만 고려한다.
각각 카티션 곱과 자연 조인을 적용시켜보면 다음과 같다.
SELECT *
FROM student, takes
WHERE student.id = takes.id;
SELECT *
FROM student NATURAL JOIN takes;결과는 다음과 같다.

하단에 위치한 자연 조인의 결과를 보면 Join을 적용한 두 릴레이션의 스키마에 나타나는 공통 속성이 반복되지 않고 한 번만 등장하는 것 을 유의해야 한다.
또한 속성이 나열된 순서도 중요한데,
카티션 곱의 경우 => (선행 릴레이션 ID, 선행 릴레이션 속성, 후행 릴레이션 ID, 후행 릴레이션 속성) 순이었다면
자연 조인의 경우 => (공통 ID, 선행 릴레이션 속성, 후행 릴레이션 속성) 순서이다.
SELECT *
FROM student NATURAL JOIN takes;자연 조인의 결과는 하나의 릴레이션이다.
개념적으로 FROM 절에 있는 "student NATURAL JOIN takes" 구문이 조인 연산이 수행되어 얻게 되는 릴레이션으로 대체된다.
그러면 생성된 릴레이션에 where 절과 select 절을 평가할 수 있다.
다음과 같이 자연 조인을 사용하여 여러 릴레이션을 결합할 수 있다.
SELECT A1, A2, ..., An
FROM r1 natural join r2 natural join ... natural join rm
WHERE P;
일반적으로 FROM 절을 다음과 같이 사용할 수도 있다.
FROM E1, E2, ..., EnEi 하나는 릴레이션 하나 거나, 자연 조인을 포함하는 "표현" 일수도 있다.
예를 들면 다음과 같이 말이다.
SELECT name, title
FROM student NATURAL JOIN takes, course
WHERE takes.course_id = course.course_id;student와 takes를 먼저 조인한 결과 릴레이션을 다시 course 릴레이션과 카티션 곱을 한다.
이후 카티션 곱의 결과에 WHERE을 통해 필터링하게 된다.
이때 자연 조인의 결과 릴레이션의 식별자 id가 course의 id와 같은지 여부를 통해 필터링한다.
자연 조인 결과의 course_id는 takes 릴레이션으로부터 나온다. student에는 course_id 속성이 없다!
따라서 WHERE 절에 명시한 takes.course_id는 자연 조인 결과 릴레이션의 course_id 필드를 참조한다.
또한 속성을 잘못 동일시하는 위험을 방지하기 위해 SQL은 어떤 행이 같아져야 하는지 확실하게 명시하는 JOIN ... USING 연산을 제공한다. 특정 속성에 대해서 일치되는 값만 이용한 자연 조인을 하는 방법이다.
SELECT name, title
FROM (student NATURAL JOIN takes) JOIN course USING (course_id);다음 연산을 고려해보자.
r1 JOIN r2 USING(A1, A2)위 연산은 r1의 t1과 r2의 t2 튜플 짝이 t1.A1 = t2.A2 인 경우를 의미한다.
1 - 2) Join 조건
ON 조건은 조인을 수행할 릴레이션에 대한 일반적인 술어를 지정할 수 있다.
이는 마치 SQL의 where과 유사하다.
조인식에 ON 조건을 포함하고 있는 다음 질의를 살펴보자.
SELECT *
FROM student JOIN takes
ON student.ID = takes.IDON 조건은 ID값이 일치하는 student 릴레이션의 튜플과 takes 릴레이션의 튜플을 JOIN 한 게 된다.
위 조인의 결과는 사실 자연 조인의 결과와 거의 같다.
왜냐하면 자연 조인 역시 student 튜플과 takes 튜플에서 서로 일치하는 튜플을 조인하기 때문이다.
유일한 차이점은 결과 릴레이션에서 ID가 student에서 1번, takes에서 1번, 총 2번 나타나게 된다.

또한 위 query는 다음과 동등하다.
SELECT *
FROM student, takes
WHERE student.ID = takes.ID;ON 조건식을 사용한 JOIN 식은 ON절의 술어를 WHERE 절로 옮긴 채로 ON조건을 사용하지 않은 동등한 식으로 표현될 수 있다.
이는 ON조건은 SQL의 중복적 특성으로 보일 수 있다.
하지만 ON 절을 사용하는 2가지 훌륭한 이유가 있다.
1) 외부 조인의 경우 ON 조건은 WHERE 조건과 다른 방식으로 동작한다.
2) 조인 조건은 ON절에 명시하고 나머지 부분은 WHERE 절에 명시하면, 가독성이 높아진다.
1 - 3) 외부 조인 (outer-join)
만약 모든 학생의 속성과 그 학생이 수강한 과목의 목록을 출력하기 위해 다음과 같은 SQL을 사용했다고 하자.
SELECT *
FROM student NATURAL JOIN takes;하지만 위 쿼리는 의도한 대로 실행되지 않는다.
student 릴레이션의 학생 중에 과목을 듣지 않는 학생이 있다면 takes 릴레이션의 어떤 튜플과도 자연 조인 조건을 만족하지 못하게 되므로 결과를 만들 수가 없다.
외부 조인 연산은 위에서 언급한 조인 연산과 유사하게 동작한다. 하지만 조인의 결과에서 빠질 수 있는 튜플을 Null 값을 통해 보존한다.
외부 조인은 3가지 유형이 있다.
- left outer join : left outer join 연산의 왼쪽에 나타난 릴레이션의 튜플만 보존한다.
- right outer join : right outer join 연산의 오른쪽에 나타난 릴레이션의 튜플만 보존한다.
- full outer join : 두 릴레이션의 모든 튜플을 보존한다.
이와 반대로 서로 같은 값을 가지고 있지 않은 튜플은 보존하지 않는 조인을 내부 조인(inner join) 연산이라 부른다.
left outer join의 동작 방식은 다음과 같다.
1. 우선 내부 조인의 결과(A)를 계산한다. (a inner join b의 결과 A생성)
2. 내부 조인의 오른쪽에(b) 있는 릴레이션의 튜플과 매칭 되지 않는 왼쪽 릴레이션(a)의 모든 튜플 t에 대해서, 조인된 결과(A)에 튜플 r을 다음과 같이 추가합니다.
- 튜플 r의 속성 중 조인 연산의 왼쪽에 있는 릴레이션에 속하는 속성을 튜플 t의 값으로 그대로 채운다.
- 튜플 r의 나머지 속성은 모두 Null로 채운다.
예를 들어 다음 쿼리를 보자.
SELECT *
FROM student NATURAL LEFT OUTER JOIN takes;
ID가 70557인 Snow 학생이 포함되어 있다. takes 릴레이션의 스키마에 나타나는 속성에 대해서는 Null 값을 포함하고 있다.
어떠한 과목도 수강하지 않은 학생은 위 쿼리에 WHERE 조건만 추가해주면 된다.
SELECT *
FROM student NATURAL LEFT OUTER JOIN takes
WHERE course_id is null;
full outer join은 내부 조인을 수행해서 결과를 얻어 낸 후, 조인 연산의 왼쪽에 있는 릴레이션의 튜플 중에서 오른쪽에 있는 릴레이션의 튜플과 연결되지 않은 튜플의 널 값을 이용해서 추가한다.
비슷한 방식으로 조인 연산의 오른쪽에 있는 릴레이션 중 왼쪽에 있는 릴레이션의 튜플과 짝이 안 된 튜플을 널값으로 채워 추가한다.
또한 Outer Join에서는 ON 조건을 사용할 수 있다.
다음 두 질의는 ID 속성이 결과에 두 번 나타나는 점을 제외하면 정확히 일치한다.
SELECT *
FROM student NATURAL LEFT OUTER JOIN takes;
SELECT *
FROM student LEFT OUTER JOIN takes
ON student.ID = takes.ID;
위에서 말했듯, ON 절은 outer join에서는 where과 다르게 동작한다.
ON조건은 외부 조인 명세의 한 부분이지만, WHERE 절은 그렇지 않다.
바로 직전에 살펴본 쿼리에서 ON절의 조건을 WHERE로 옮기고 ON절의 술어에는 true를 전달해보자.
SELECT *
FROM student LEFT OUTER JOIN takes
ON student.ID = takes.ID;
SELECT *
FROM student LEFT OUTER JOIN takes
ON true
where student.ID = takes.ID;각각의 결과를 보면 다음과 같다.
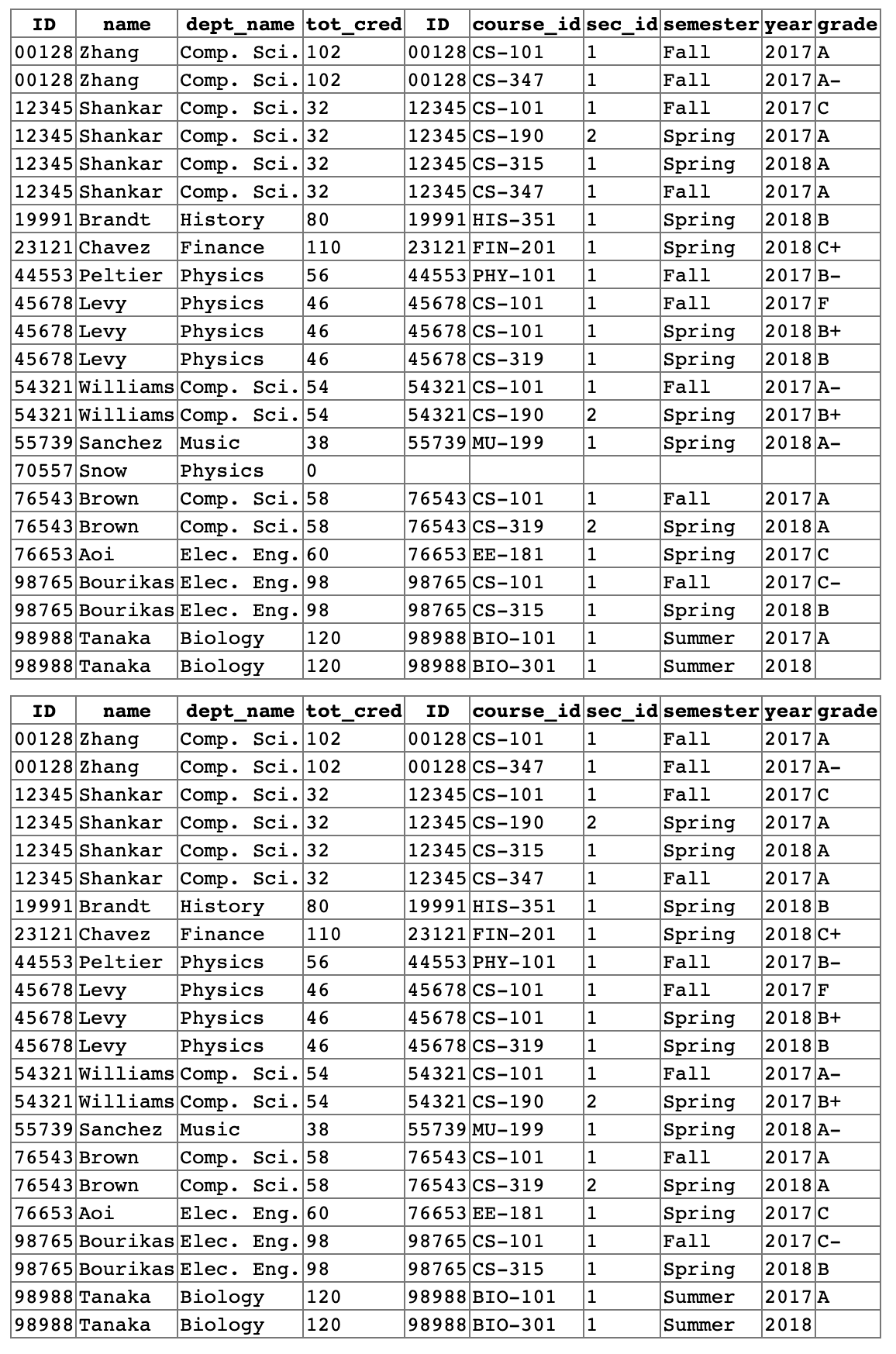
ON조건을 이용한 첫 릴레이션을 보면 (70557, Snow, Physics, 0, null, null, null, null, null, null) 튜플을 포함한다.
왜냐하면 takes 릴레이션에는 ID=70557을 만족하는 튜플이 존재하지 않기 때문이다.
하지만 두 번째 결과 릴레이션에서는 모든 튜플이 조인 조건을 true로 만족하기 때문에 outer join 연산이 null값을 이용한 튜플 추가를 수행하지 않는다. 이러한 경우 outer join은 카티션 곱과 같이 동작한다.
따라서 다음과 같이 카티션 곱과 on 절을 true 두고 카운트 해보면 결과값이 동일하다.
SELECT count(*)
FROM student, takes;
SELECT count(*)
FROM student LEFT OUTER JOIN takes
ON true;
takes 릴레이션에는 ID=70557 조건을 만족하는 튜플이 존재하지 않기 때문에 name="Snow"로 outer join을 수행할 때마다 student.ID 와 takes.ID는 서로 다른 값을 가지게 되고, 이러한 튜플은 where 절의 술어에 의해서 제거된다.
결과적으로 두 번째 질의에서는 Snow 학생은 결과에 포함되지 않는다.
1 - 4) 조인의 종류와 조인 조건
일반 조인과 외부 조인을 구별하기 위해 SQL에서는
일반적인 조인을 -> 내부 조인이라는 용어로 사용한다. 따라서 inner라는 단어는 선택적으로 사용된다.
즉, 일반적인 조인의 종류에서 outer가 붙지 않으면 전부 inner 조인이다.
이와 비슷하게 inner join은 natural inner join과 동등하다.
2. View
특정 사용자가 필요로 하는 개인화된 "가상"의 릴레이션 모음을 생성할 수 있다.
이러한 릴레이션은 질의의 결과를 개념적으로 포함하고 있다.
즉, 가상 릴레이션은 미리 계산해서 저장하는 것 이 아니라, 사용할 때마다 질의를 수행해서 결과를 얻어낸다.
주어진 실제 릴레이션 집합에 대해 많은 수의 뷰를 만드는 것이 가능하다.
2 - 1) View 정의
다음과 같이 create view를 사용하면 된다.
create view v as <query expression>;query expression 부분은 적합한 질의 표현식이다. 뷰의 이름은 v에 해당된다.
예를 들어 사무원이 instructor 릴레이션에 접근해서는 안되면, 다음 정의와 같이 faculty라는 view를 생성하면 된다.
CREATE VIEW faculty as
SELECT ID, name, dept_name
FROM instructor;
2 - 2) SQL 질의에서 뷰 사용
일단 뷰를 정의하면, 그 뷰가 생성하는 가상 릴레이션을 가리키기 위해 뷰의 이름을 사용할 수 있습니다.
예를 들어 2017년도 과목을 찾는 질의를 뷰를 통해 다음과 같이 작성할 수 있습니다.
(physics_fall_2017은 뷰 이름)
SELECT course_id
FROM physics_fall_2017
WHERE buildin = 'Watson';
직관적으로 뷰의 결과 릴레이션을 저장하면, 뷰를 정의하기 위해 사용한 릴레이션이 수정될 경우 해당 뷰 릴레이션의 상태는 최신이 아니게 된다.
이러한 문제를 없애기 위해 보통은 뷰를 다음과 같이 구현한다.
뷰를 정의하면 데이터베이스 시스템은 그 뷰의 정의를 저장한다. 그리고 뷰 릴레이션이 나타날 때마다 그 자리에 저장된 질의 표현식을 바꿔 넣는다.
2 - 3) 실체화 뷰
특정 데이터베이스 시스템은 뷰 릴레이션을 저장하는 방법을 제공한다.
이러한 경우 뷰를 정의하는 데 사용한 릴레이션이 수정되어도 뷰는 최신 상태를 유지한다.
이러한 뷰를 실체화 뷰(materialized views)라 부른다.
뷰가 실체화되어 있다면 그 결과는 데이터베이스에 저장되어 뷰를 사용하는 질의를 다시 계산하는 대신 미리 계산된 뷰 결과를 사용하여 잠재적으로 훨씬 더 빠르게 실행할 수 있을 것이다.
또한 이러한 실체화 뷰를 최신 상태로 유지하는 과정을 실체화 뷰 관리, 뷰 관리라고 부른다.
2 - 4) 뷰의 갱신
뷰를 통해 데이터베이스를 수정하려면 그 데이터베이스의 논리적인 모델 내의 실제 릴레이션에 수정을 해야 하는데, 여러 문제점이 발생한다.
잠시 위에서 살펴봤던 faulty 뷰를 생각해보자. 다음과 같이 이름이 들어가는 곳에 사용할 수 있다.
insert into faculty
values ('360765', 'Green', 'Music');instructor 릴레이션이 faculty 뷰를 구성하는 데이터베이스의 실제적인 릴레이션 이기 때문에, 이러한 삽입은 instructor 릴레이션에 수행되어야 한다.
문제는 instructor 튜플에 삽입할 때 salary 값이 없다.
이를 해결하는 방법으로는
1) 삽입을 거부하고 사용자에게 오류 메시지를 출력한다.
2) 해당 값을 null로 삽입한다.
따라서 일반적으로 View 릴레이션에 대한 변경을 허용하지 않는다.
3. 트랜잭션
트랜잭션은 질의문과 갱신 문의 순차(sequence)로 이루어져 있다.
SQL 표준에서는 SQL문이 실행되는 순간에 암묵적으로 트랜잭션이 시작된다고 명시하고 있다.
트랜잭션은 다음의 SQL문 중 하나로 끝난다.
▶ Commit work
현재 수행 중인 트랜잭션을 commit 한다. 즉 트랜잭션이 수행한 갱신을 DB에 영구적으로 반영한다.
트랜잭션이 완료된 후에는 새로운 트랜잭션을 자동으로 시작한다.
▶ Rollback work
현재 수행중인 트랜잭션을 롤백한다. 즉 트랜잭션에서 SQL문에 의해 수행된 모든 갱신을 취소한다.
DB는 트랜잭션이 수행되기 전 상태로 돌아간다.
DB는 오류가 발생하거나, 정전, 시스템 충돌 등으로 인한 장애가 발생한 상황에서 트랜잭션이 커밋을 수행하지 않았다면 롤백하는 것을 보장한다. 정전 같은 경우 롤백은 시스템이 재시동될 때 수행된다.
하나의 트랜잭션의 모든 동작이 수행되어서 커밋을 하거나, 모든 동작을 수행하지 못한 경우 rollback을 수행함으로써 데이터베이스는 트랜잭션의 atomic(원자성)인 성질을 보장한다.
MySQL, PostgreSQL을 포함한 많은 SQL 구현에서는, 기본적으로 각 SQL문은 트랜잭션이 되고, 그것이 수행되자마자 커밋이 된다.
하지만 각 SQL 문의 auto commit은 트랜잭션이 여러 개의 SQL로 구성된 경우에는 해제되어야 한다.
4. 무결성 제약 조건
무결성 제약 조건(Integrity constraint)은 권한이 주어진 사용자가 데이터베이스에 변경을 가할 때, 데이터 일관성에 손실이 생기지 않음을 보장하는데 이용된다.
무결성 제약 조건의 예시는 다음과 같다.
- 교수 이름은 null이 될 수 없다
- 서로 다른 교수가 같은 ID값을 가질 수 없다
- course 릴레이션에서 모든 학과 이름은 department 릴레이션의 학과 이름과 일치해야 한다.
- 학과의 예산은 $0.00보다 항상 커야 한다.
무결성 제약 조건은 일반적으로 데이터베이스 스키마 설계 과정의 일부로 인식된다.
무결성 제약 조건은 create table 명령과 함께 사용될 수도 있지만, alter table table-name add constraint 명령을 통해서도 이미 존재하는 릴레이션에 추가할 수도 있다.
4 - 1) 단일 릴레이션에 관한 제약 조건
create table 명령을 수행할 때 허용하는 무결성 제약조건은 다음과 같다.
- not null
- unique
- check(<술어>)
4 - 2) Not Null 제약 조건
Null은 모든 도메인의 값이 될 수 있다. 즉, 모든 속성에 가능한 값이다.
하지만 어떤 속성에는 Null 값을 허용하고 싶지 않을 수 있다. 이럴때 다음과 같이 사용한다.
name varchar(20) not nullnot null명세는 속성에서 Null값을 삽입하지 못하도록 한다. 이는 도메인 제약 조건의 한 예이다.
특히 릴레이션 스키마의 Primary Key 속성은 Null 값을 허용하지 않는 것이 필수적이다.
이런 경우 not null을 명시해주면 된다.
4 - 3) Unique 제약 조건
unique(A1, A2, ..., Am)unique 명세는 속성 A1, A2,..., Am 이 수퍼 키를 구성한다는 것을 나타낸다.
즉, 릴레이션의 어떠한 두 개의 튜플도 나열된 위 속성의 값이 같을 수 없다.
하지만 unique 조건이 있어도 속성은 not null을 선언하지 않는 이상 null값을 가질 수 있다.
null은 어떠한 값과도 같지 않음을 기억하자!
4 - 4) Check 절
릴레이션의 정의를 적용할 때 check(P)절은 릴레이션의 모든 튜플이 충족해야 하는 술어 P를 명시한다.
일반적으로 check 절은 속성 값이 명시된 조건을 만족하는 것을 보장하는 데 사용된다.
실상은 강한 타입 기능을 제공하는 것과 같다.
다음 예시를 살펴보자
CREATE TABLE section (
course_id varchar(8),
sec_id varchar(8),
semester varchar(6),
year numeric(4, 0),
building varchar(15),
room_number varchar(8),
time_slot_id varchar(4),
primary_key (course_id, sec_id, semester, year),
check (semester in ('Fall', 'Winter', 'Spring', 'Summer'))
);위 쿼리문에서 check 절은 semester가 Fall, Winter, Spring, Summer 중 하나여야 한다는 열거형 타입을 정의하는 데 사용했다.
Null 값은 check 절을 평가할 때 조금 예외적이다.
거짓이 아니면 check절을 만족하므로 unknown으로 평가되는 절은 위반이 아니다.
Null이 필요하지 않은 경우 not null 제약조건을 추가하면 된다.
일반적으로 단일 값 속성에 대한 제약은 해당 속성과 함께 check 절을 명시하지만, 복잡한 제약의 경우 create table 문 끝에 명시한다.
4 - 5) 참조 무결성
주어진 속성의 집합에 대한 한 릴레이션의 값이 또 다른 릴레이션의 특정한 속성 집합에 대해 반드시 나타나는 경우가 있다.
그러한 경우를 참조 무결성 제약 조건이라 부른다.
참조하는 릴레이션 에서의 외래 키는 참조된 릴레이션의 주키를 이루는 참조 무결성 제약의 한 형태이다.
예를 들어 foreing key 절을 사용할 때를 생각해보자.

foreign key (dept_name) references department위와 같은 외래 키 선언은 각 과목 튜플에 명시된 학과 이름이 department 릴레이션에 존재해야만 한다는 것이다.
이러한 제약 조건이 없다면 존재하지 않는 학과 이름을 입력하는 것 이 가능해진다.
일반적으로 외래 키는 참조된 테이블의 primary key를 사용하며,
변형된 references 절을 지원한다. MySQL 같은 경우 독특하게 변형된 references절만 지원한다.
foreign key (dept_name) references department (dept_name)
외래 키는 호환 가능한 속성의 집합을 참조해야 함에 주의하자.
즉, 속성 수가 같아야 하고, 해당 속성의 데이터 타입이 서로 호환 가능해야 한다.
추가적으로, 속성 바로 뒤에 외래 키를 형성하도록 명시해줄 수도 있다.
dept_name varchar(20) references department
참조 무결성 제약 조건이 위반되었을 때 기본 처리 방식은, 제약 조건을 위반한 동작을 거절하는 것이 기본이다.
하지만, foreing key 절은 참조된 릴레이션에서 삭제하거나 갱신 등 제약 조건 위반이 발생하면 그 동작을 거부하는 대신, 시스템이 참조하는 릴레이션의 튜플을 변환하는 절차를 저장함으로써 나중에 복원할 수 있다.
예를 들어 다음 쿼리를 살펴보자.
foreign key (dept_name) references department
on delete cascade
on update cascadedepartment 릴레이션에서 dept_name이 있는 해당 튜플을 삭제했다고 치자.
그러면 참조하는 릴레이션에서 참조 대상이 사라진 것이다. 즉, 참조 무결성 제약 조건 위반이다.
=> department 릴레이션의 튜플 삭제는 삭제된 학과를 참조하는 course 릴레이션의 튜플도 "연쇄(cascade)" 삭제하게 된다.
update cascade도 마찬가지이다.
참조되는 릴레이션의 튜플에서 업데이트하면, 참조하는 course 릴레이션의 튜플도 업데이트시킨다.
4 - 6) 제약 조건 명명
무결성 제약 조건에 이름을 추가해줄 수 있다. 이러한 이름은 제약 조건을 삭제할 때 유용하다.
예를 들어 instructor 릴레이션의 salary 속성에 대한 check 제약 조건에 minsalary라는 이름을 할당하려면 다음과 같이 수정할 수 있다.
salary numeric(8, 2) constraint minsalary check(salary > 29000)삭제할 때는 다음과 같이 쿼리를 날리면 된다.
alter table instructor drop constraint minsalary;
4 - 7) 트랜잭션 수행 중 무결성 제약 조건 위반
무결성 재약 조건은 트랜잭션 중간 단계가 아닌, 트랜잭션의 마지막 단계에서 검사 되어야 한다.
제약 조건은 대안적인 방법으로 연기 가능(deferrable)하게 명시될 수 있다.
예를 들어 다음과 같이 명시하면
set constraints constraint-list deferred명시된 제약 조건 검사를 트랜잭션의 마지막 단계로 연기시킨다.
위에서 constaint-list에 명시될 제약조건들은 이름을 지정한 제약조건이어야 한다.
물론 기본은 제약조건을 즉시 검사하는 것이며, 많은 데이터베이스 시스템은 제약조건 연기를 지원하지 않는다.
'CS > DB (2022-1)' 카테고리의 다른 글
| [DB] E-R 모델을 사용한 데이터베이스 설계 (0) | 2022.10.06 |
|---|---|
| [DB] 고급 SQL (1) | 2022.10.04 |
| [DB] 중급 SQL - 2 (1) | 2022.09.30 |
| [DB] 관계형 모델 소개 (0) | 2022.09.26 |
| [DB] 트랜잭션 (Transaction) - 특성, ACID, 연산, 상태 (0) | 2022.08.30 |
댓글