[알고리즘] 다익스트라, 프림 알고리즘의 차이점

다익스트라 알고리즘과, 프림 알고리즘을 공부하면서 전체적인 틀이 BFS와 유사하지만, 약간의 차이점들이 있음을 느꼈다.
이를 정리겸 블로그에 글을 남겨본다.
dist[] or d[] 의 의미 차이
통상적으로 두 알고리즘을 설명하는 책 이라면 dist[] 혹은 d[] 배열을 사용하여 알고리즘을 설명한다.
문제는 프림과 다익스트라 모두 dist 배열을 사용하기 때문에 처음 공부하는 입장에서는 같은 의미의 배열인 줄 알고 오해하는 경우가 있기 마련이다. (내가 처음 배울때 그랬다...)
참고로 다음 설명에서 나오는 집합 S는 이미 선택된 정점들의 집합을 의미한다.
▶ Prim 에서의 dist[]
프림 알고리즘에서 각 정점에 기록된 값은 해당 정점을 집합S에 있는 정점과 연결하는데(s에 포함시키는데) 드는 최소비용 이다. 배열 dist[] 이용하여 표현한다.
각 정점의 연결비용, 즉 dist[v]의 값은 여러번 바뀐다. ∞에서 바뀌는 시점은 이 정점이 처음으로 집합S에 연결 가능한 시점이고, ∞이 아닌 수에서 바뀌는 시점은 이미 연결가능한 상태가 되었지만 더 좋은 연결 방법이 발견되었을 때 이다.
▶ Djikstra 에서의 dist[]
다익스트라 알고리즘에서 dist는 시작정점 r에서 해당정점 v 까지의 최단거리를 표현하는 배열이다.
이를 그림으로 확인하면 다음과 같다.
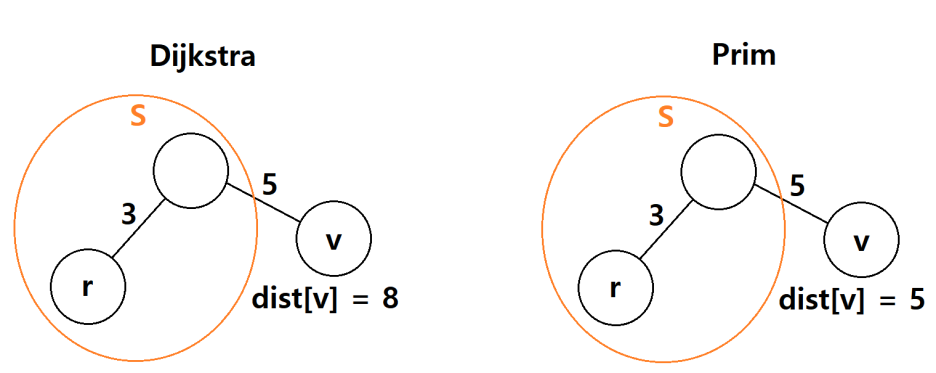
요약하자면,
프림알고리즘 에서는 d[v]가 정점 v를 신장트리에 연결하는 최소비용을 위해 사용되는 반면, 다익스트라 알고리즘에선는 d[v]가 정점 r에서 v에 이르는 최단거리를 위해 사용한다.
알고리즘 확인
이러한 차이로 인하여 두 알고리즘의 구조가 거의 유사함에도 불구하고 차이가 생기는 부분이 있다. 이를 알아보자.
우선 두 알고리즘을 sudo code로 확인 해 보자.
▶ Prim 알고리즘
Prim(G, r)
// G = (V, E): 주어진 그래프
// r: 시작 정점
{
S ← Ø: // S: 정점 집합
for each u ∈ V
dist[u] ← ∞;
d[r] ← 0;
while(S≠V) { // n회 순환
u ← extractMin(V-S, dist);
s ← S ∪ {u};
for each v ∈ L(u) // L(u) : 정점 u의 인접 정점 집합
if(v ∈ V-S and w(u, v) < dist[v]) then {
dist[v] ← w(u, v);
}
}
}
extractMin(Q, d[]){
집합 Q에서 d값이 가장 작은 정점 u를 반환한다;
}▶ Dijkstra 알고리즘
Dijkstra(G, r)
// G = (V, E): 주어진 그래프
// r: 시작 정점
{
S ← Ø: // S: 정점 집합
for each u ∈ V
dist[u] ← ∞;
d[r] ← 0;
while(S≠V) { // n회 순환
u ← extractMin(V-S, dist);
s ← S ∪ {u};
for each v ∈ L(u) // L(u) : 정점 u의 인접 정점 집합
if(v ∈ V-S and dist[u] + w(u, v) < dist[v]) then {
dist[v] ← dist[u] + w(u, v);
}
}
}
extractMin(Q, d[]){
집합 Q에서 d값이 가장 작은 정점 u를 반환한다;
}두 알고리즘은 거의 동일한데 딱! 한줄만 다르다.
다익스트라에서 다음 한줄이 프림과 다르다.
if(v ∈ V-S and dist[u] + w(u, v) < dist[v]) then {
dist[v] ← dist[u] + w(u, v);
}dist[u] 값을 더하여 비교한다는 의미는 Djkstra 에서 dist[] 배열의 의미가 시작정점 r 에서 도착지점인 v까지의 최단경로의 길이를 저장한다는 의미에 부합한다.
즉, 기존의 경로값 dist[u]에 새로 추가된 edge의 weight w(u, v)를 더한값 과 그냥 기존의 dist[v]를 비교하여 더 작은 값으로 정하겠다는 의미이다.
이와는 다르게 Prim 알고리즘 에서는 단지 이미 선택된 노드들의 집합 S에서 해당 노드 까지의 거리만을 의미한다.
if(v ∈ V-S and w(u, v) < dist[v]) then {
dist[v] ← w(u, v);
}dist[v] 만을 비교하고 있음을 알 수 있다.