내돈내고 내가 공부한것을 올리며, 중요한 단원은 저 자신도 곱씹어 볼겸 상세히 기록하고 얕은부분들은 가겹게 포스팅 하겠습니다.

1) 섹션19
이번 단원에서는 modern C++에서의 필수 요소들에 대하여 배웠다.

19-1 람다 함수와 std::funtion std::bind, for_each
이번에는 현대적 프로그래밍의 유연성을 높혀주고, 부담을 줄여주는 람다함수 그리고 std::funtion에 대하여 알아보자.
람다함수는 '익명함수' 라고도 불린다. C++뿐만 아니라 다른 언어들에서도 사용하고 있다.
우선 구조를 알아보자.

#include <iostream>
#include <vector>
#include <string>
using namespace std;
int main(void)
{
// lambda-introducer []
// lambda-parameter-decalration ()
// lambda-return-type-clause ->
// compound-statement {}
auto func = [](const int& i) -> void { cout << "Hello, World"<< i << endl; };
func(123);
// 진정한 람다함수의 효과
[](const int& i) -> void { cout << "Hello, World"<< i << endl; } (1234);
return 0;
}위의 코드에서 auto func는 포인터 변수이다. 이를 통해 함수를 사용하기 보다는, 직접 함수에 인자로써 람다함수를 사용할 수 있다.
직접 사용하기 때문에 함수의 이름이 필요 없어 익명함수 라고도 부르며, 또한 전체 코드중에서 한번만 사용되는 함수같은경우 사용하면 좋다. 결과는 다음과 같다.

다음으로는 introducer인 []를 사용하는 예를 살펴보자.
int main(void)
{
// lambda-introducer []
// lambda-parameter-decalration ()
// lambda-return-type-clause ->
// compound-statement {}
{
string name = "JackJack";
[&]() {std::cout << name << endl; } ();
// 람다함수가 정의된 영역 안에서 introducer안에다가 &를 삽입해두면
// 외부의 값을 참조로 갖어온다. 람다함수 안에서 사용할 수 있다.
[=]() {std::cout << name << endl; } (); // name을 copy하여 사용
}
return 0;
}위의 코드를 보면 [ ] 안에 &가 들어가 있다. 이는 람다함수 외부의 값을 참조로 갖어오겠다는 말이다.
따라서 string name을 참조형으로 갖어와 사용한다. = 의 경우 name을 복사하여 갖어온다.
결과로는 JackJack 이 2번 출력된다.
다음으로는 STL과 함께 사용하는 코드를 살펴보자.
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
#include <functional>
using namespace std;
int main(void)
{
// lambda-introducer []
// lambda-parameter-decalration ()
// lambda-return-type-clause ->
// compound-statement {}
// STL과 같이 사용
vector<int> v;
v.push_back(1);
v.push_back(2);
auto func2 = [](int val) {cout << val << endl; }; // return 이 void형이면 -> 는 생략가능
for_each(v.begin(), v.end(), func2);
for_each(v.begin(), v.end(), [](int val) {cout << val << endl; }); // v의 원소마다 적용
cout << []() -> int {return 1; }() << endl; // body에서 1을 return
return 0;
}위의 코드를 보면 func2 포인터 변수로 람다함수의 주소를 받고 있다. 이렇게 받음 func2를 for_each함수의 인자로 전달하고 있다.
사실 이렇게 사용하려고 람다함수를 사용하는 것 이 아니라는것을 위에서도 봤다.
그냥 람다함수를 통으로 for_each함수 안에 삽입하여 사용하는것이 원래 의도이다.
참고로 람다함수는 return형이 없을경우 -> void 표기를 생략할 수 있다.
std::function에 대하여도 알아보자.
C++ 에서는 callable들을 객체의 형태로 보관할 수 있는 std::function이라는 class를 제공합니다.
참고로 callable은 ()를 사용하여 호출할수있는 모든것을 callable라고 합니다.
함수 포인터를 좀더 체계화 시킨것 이라 생각하면 좋다 하셨다.
#include <iostream>
#include <functional>
#include <string>
int doSomething(const std::string& a) {
std::cout << "Func1" << a << std::endl;
return 0;
}
struct S {
void operator()(char c) { std::cout << "Func2" << c << std::endl; }
};
int main() {
std::function<int(const std::string&)> f1 = doSomething;
std::function<void(char)> f2 = S();
std::function<void(void)> f3 = []() { std::cout << "Func3" << std::endl; };
f1("hello");
f2('a');
f3();
}위의 코드를 실행한다면 결과는 다음과 같다.

function의 object를 만드는 방식을 살펴보자. f1의 경우 funtion<int(const std::strinn&)> f1 에서 const std::strinn&는 doSomething()의 매개변수이며, int는 doSomething()의 반환형과 같다.
f2의 경우 functor인 S는 () 함수의 매개변수가 char이고, 반환형이 void이기 때문에 std::funtion<void(char)> f2 라고 선언했다.
f2의 경우 람다함수의 인자와 반환형이 없기 때문에 void로 선언한다.
다음은 bind에 대하여 알아보자.
int main(void)
{
// STL과 같이 사용
vector<int> v;
v.push_back(1);
v.push_back(2);
auto func2 = [](int val) {cout << val << endl; };
for_each(v.begin(), v.end(), func2);
for_each(v.begin(), v.end(), [](int val) {cout << val << endl; }); // v의 원소마다 적용
cout << []() -> int {return 1; }() << endl; // body에서 1을 return
std::function<void(int)> func3 = func2;
func3(123); // functer처럼 사용
std::function<void(void)> func4 = std::bind(func3, 456);
func4();
return 0;
}func3의 경우 매개변수로 int를 지정해줘야 하기 때문에 조금 귀찮다. 이럴경우 func4처럼 bind하여 사용하면 된다.
func3에는 int를 하나 넘겨 받게 되있다. 그 int를 아예 하나 bind 해버리는 것 이다.
정작 func4는 func3가 전달되는대 매개변수가 없다. void 이다. 왜냐하면 456이 그냥 들어가도록 묶여있기 때문이다.
이번에는 placeholder에 대하여 알아보자.
void add(int x, int y) {
std::cout << x << " + " << y << " = " << x + y << std::endl;
}
int main() {
auto add_with_2 = std::bind(add, 2, std::placeholders::_1);
add_with_2(3);
add_with_2(3, 4);
}위의 코드를 보면 add함수, 인자1, 인자2 를 bind 로 묶어주고 있다.
add_with_2를 호출시 add함수 호출과 동시에 2를 매개변수 x에 자동 전달한다.
매개변수 y의 경우 placeholder::_1 로 두었기에 이를통해 전달된다.
add_with_2(3) 이라 했으니 매개변수 y에는 3이 전달되며 결과로는 2 + 3 = 5가 될것이다.
add_with_2(3, 4)의 경우 4는 무시되며 첫번째 인자인 3만 placeholder를 통해 2 + 3 = 5가 된다.
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
#include <functional>
using namespace std;
void goodbye(const string& s)
{
cout << "Goodbye " << s << endl;
}
class Object {
public:
void hello(const string& s)
{
cout << "Hello" << s << endl;
}
};
int main(void)
{
{
Object instance;
auto f = std::bind(&Object::hello, &instance, std::placeholders::_1);
// 함수의 포인터 필요, class의 instance가 필요, hello의 매개변수가 1개이니 placeholder 1개
f(string("World"));
auto f2 = std::bind(&goodbye, std::placeholders::_1); // 그냥 함수 bind
f2(string("Worlds"));
}
return 0;
}f 에서는 class object에 속해있는 hello라는 함수를 실행 시키는데, 이 hello는 멤버함수이다.
따라서 hello가 실행되려면 object의 instance가 하나 필요하다. 실행이 되려면 this포인터를 갖고있는 instance가 필요한 것 이다.
마지막으로 hello함수는 매개변수가 하나이다. 따라서 placeholder하나를 잡아주는 것 이다.
<class의 맴버함수와 instance 를 bind>
f2 에서는 bind를 할때 goodbye라는 함수의 포인터를 이용하고, 함수의 매개변수가 1개 있으니 placeholder를 1개 사용한다.
<그냥 함수도 bind가능>
전체 main.cpp
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
#include <functional>
using namespace std;
void goodbye(const string& s)
{
cout << "Goodbye " << s << endl;
}
class Object {
public:
void hello(const string& s)
{
cout << "Hello" << s << endl;
}
};
int main(void)
{
// lambda-introducer []
// lambda-parameter-decalration ()
// lambda-return-type-clause ->
// compound-statement {}
auto func = [](const int& i) -> void { cout << "Hello, World"<< i << endl; };
func(123);
// 진정한 람다함수의 효과
[](const int& i) -> void { cout << "Hello, World"<< i << endl; } (1234);
{
string name = "JackJack";
[&]() {std::cout << name << endl; } ();
// 람다함수가 정의된 영역 안에서 introducer안에다가 &를 삽입해두면
// 외부의 값을 참조로 갖어온다. 람다함수 안에서 사용할 수 있다.
[=]() {std::cout << name << endl; } (); // name을 copy하여 사용
}
// STL과 같이 사용
vector<int> v;
v.push_back(1);
v.push_back(2);
auto func2 = [](int val) {cout << val << endl; };
for_each(v.begin(), v.end(), func2);
for_each(v.begin(), v.end(), [](int val) {cout << val << endl; }); // v의 원소마다 적용
cout << []() -> int {return 1; }() << endl; // body에서 1을 return
std::function<void(int)> func3 = func2;
func3(123);
std::function<void(void)> func4 = std::bind(func3, 456);
func4();
{
Object instance;
auto f = std::bind(&Object::hello, &instance, std::placeholders::_1);
// 함수의 포인터 필요, class의 instanc가 필요, hello의 매개변수가 1개이니 placeholder 1개
f(string("World"));
auto f2 = std::bind(&goodbye, std::placeholders::_1); // 그냥 함수 bind
f2(string("Worlds"));
}
return 0;
}실행 결과는 다음과 같다.
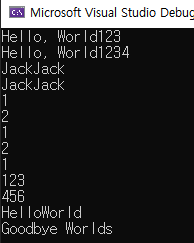
19-2 C++ 17 함수에서 여러 개의 리턴값 반환하기
여러개의 return 값이라니. C에 이어서 C++ 까지 연속적으로 배워왔지만 진짜 신기한 기능인것 같다.
먼저 tuple을 사용하는 예전방식을 확인한 후, 좀더 최신 방법을 알아보자.
#include <iostream>
#include <tuple>
#include <string>
using namespace std;
tuple<int, int> my_func(){
return tuple<int, int>(123, 456);
}
int main()
{
tuple<int, int> result = my_func();
cout << get<0>(result) << " " << get<1>(result) << endl;
return 0;
}tuple을 사용하는 방식의 코드이다. 실행하면 우리가 예상한대로 결과가 나온다.
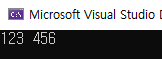
위의 코드를 auto 를 사용하면 조금더 편해진다.
auto my_func(){
return tuple<int, int>(123, 456);
}
int main()
{
auto result = my_func();
cout << get<0>(result) << " " << get<1>(result) << endl;
return 0;
}결과는 이전과 같게 나온다. 이번에는 return 값으로 정수 3개를 반환한다 생각해보자.
그렇다면 my_func()안에서 <int, int, int> 하고 int를 3번씩이나 타이핑 해야한다는 단점이 있다. 이를 극복해보자.
auto my_func(){
return tuple(123, 456, 789);
}
int main()
{
auto result = my_func();
cout << get<0>(result) << " " << get<1>(result) << " " << get<2>(result) << endl;
return 0;
}위와 같이 tuple뒤에 <> 없이 사용할수가 있다. 하지만 아직도 불편한 점이 있다면 다음번에 tuple(123, 456, 789, 10)처럼 하나가 더 늘어났을때, get<3>(result)를 또하나 늘려줘야 한다는 점이다. 다음과 같이 변경해보자.
auto my_func(){
return tuple(123, 456, 789, 10);
}
int main()
{
//auto result = my_func();
//cout << get<0>(result) << " " << get<1>(result) << " " << get<2>(result) << endl;
auto [a, b, c, d] = my_func();
cout << a << " " << b << " " << c << " " << d << " " << endl;
return 0;
}결과는 생각한것과 같이 나온다.
19-3 std thread와 멀티쓰레딩 기초
이번시간에 배운 내용은 직전년도 학교에서 시스템프로그래밍 시간에 빡시게 공부해서 A+받았던 과목의 내용이라.
간략하게 다시 점검한다는 느낌으로 들었습니다. 자세한 필기는 생략하겠습니다.
#include <iostream>
#include <chrono>
#include <thread>
#include <vector>
#include <mutex>
// semaphore는 없음
using namespace std;
int main()
{
cout << "Logical process = " << std::thread::hardware_concurrency() << "\n";
cout << "Thread id = " << std::this_thread::get_id() << "\n";
const int num = std::thread::hardware_concurrency();
std::thread t1 = std::thread([] {
cout << std::this_thread::get_id() << '\n';
while (true);
});
t1.join(); // t1이 끝날 때까지 기다린다.
std::cout << "\n\n\n" << "Multithread test\n\n";
mutex mux;
auto work = [&](const string& name)
{
for (int i = 0; i < (num / 2); ++i)
{
std::this_thread::sleep_for(std::chrono::milliseconds(300));
mux.lock(); // mutual exclusion - critical section!
cout << name << "'s id = " << std::this_thread::get_id() << "\n";
mux.unlock();
}
};
std::thread t2 = std::thread(work, "JackJack");
std::thread t3 = std::thread(work, "Dash");
t2.join();
t3.join();
}멀티스레딩 기법의 아주 기본적인 면을 공부할 수 있었다. 알고있었던 내용들이라 지장없이 넘어갈 수 있었다.
19-4 레이스 컨디션, std::atomic, std::scoped_lock
같은 메모리 공간을 공유하기에 문제점이 발생하는데 이를 Race condition 이라 부른다.
또한 이런 문제가 발생하는 공유 메모리에 접근하는 코드를 critical section이라고 부른다.
Race_condition을 명확히 이해하려면 어셈블리어의 기본이 필요한데, 이는 블로그주인장인 내가 따로 글을 써볼 예정이다.
우선 간단히 레이스 컨디션이 발생하는 이유를 설명해 보면, 우리가 숫자를 더할때는 총 3단계를 거치는데,
1) 메모리에서 값을 CPU로 이동
2) CPU에서 연산
3) CPU에서 다시 메모리로 이동.
이러한 방식으로 연산이 진행하는데 thread1에서 더하는 도중에 thread2 또한 연산할려 들었기 때문에 값에 차이가 나버린다.
이를 해결하기 위해서는 atomic<int>가 필요하다.
#include <iostream>
#include <mutex>
#include <atomic>
#include <thread>
using namespace std;
int main()
{
atomic<int> shared_memory(0);
auto count_func = [&]() {
for (int i = 0; i < 1000; ++i)
{
std::this_thread::sleep_for(std::chrono::microseconds(1));
shared_memory++;
}
};
thread t1 = thread(count_func);
thread t2 = thread(count_func);
t1.join();
t2.join();
cout << "After" << endl;
cout << shared_memory << '\n';
}위의 코드를 실행하면 정상적이 2000이 결과값으로 나온다.
atomic의 명확한 의미는 내가 시스템프로그래밍 수업때 공부했던 자료를 아주일부만 첨부하겠다.

이러한 Atomic을 사용하면 일반 int보다는 조금이라도 느려지는 경향이 있다.
그럼 이러한 atomic을 안쓰는 방식은 없을까? 앞에서 배웠던 Lock을 이용하는 방식이 있을 것 이다.
mutex mtx;
int main()
{
int shared_memory(0);
auto count_func = [&]() {
for (int i = 0; i < 1000; ++i)
{
std::this_thread::sleep_for(std::chrono::microseconds(1));
mtx.lock();
shared_memory++;
mtx.unlock();
}
};
thread t1 = thread(count_func);
thread t2 = thread(count_func);
t1.join();
t2.join();
cout << "After" << endl;
cout << shared_memory << '\n';
}동시에 하나의 thread만이 mutex에 들어갈수 있기 때문에 atomic을 사용한것과 동일한 결과를 얻을 수 있다.
교수님은 말씀 없으셨지만 배웠던 내용이기에 내가좀더 살을 더해보면, mutex의 경우 병렬성이 매우 떨어진다는 단점이 생긴다.
동시에 일을 해야할 판에 mutex를 두고 thread1이 일을 끝낼때까지 thread2는 기다리면서 대기하고 있다.
따라서 병렬성이 떨어지는 단점이 있다.
또한 mutex는 항상 lock을 한후 다 사용한 후 unlock해줘야 한다는 단점이 있다.
이를 좀더 쉽게 사용하기 위해 std::lock_guard 를 사용한다.
auto count_func = [&]() {
for (int i = 0; i < 1000; ++i)
{
std::this_thread::sleep_for(std::chrono::microseconds(1));
std::lock_guard lock(mtx);
shared_memory++;
}
};{ }안의 범위 안에서 lock변수를 선언해 주었기에 범위를 벗어나면서 자동 소멸된다. 따라서 unlock해줄 필요 없다.
여기서 더 나가아 C++ 17에서는 scoped_lock 이 생겼으며 이를 권장한다고 한다.
auto count_func = [&]() {
for (int i = 0; i < 1000; ++i)
{
std::this_thread::sleep_for(std::chrono::microseconds(1));
std::scoped_lock lock(mtx); // C++17 부터는 scoped_lock을 권장한다. 범위 넘어가면 자동으로 unlock
shared_memory++;
}
};19-5 작업 기반 비동기 프로그래밍
future와 promise는 처음보는 방식이였다. 미래(future)에 thread가 자신의 일을 다 수행항후 결과값을 돌려주겠다는 약속(promise)을 하는것이다.
#include <iostream>
#include <future>
#include <thread>
using namespace std;
int main()
{
// thread
{
int result;
std::thread t([&] {result = 1 + 2; });
t.join(); // thread가 일을 끝날때까지 기다림
cout << result << endl;
}
// task-based parallellism
{
// std::future<int> fut = ...
auto future = std::async([] {return (1 + 2); }); // main thread와 별도로 작업수행
cout << future.get() << '\n'; // return이 바로된다는 보장이 없다. 미래에 async작업이 끝나면 뭔가를 받아오겠다.
// get으로 int값이 나옴. 참고로 get코드가 실행되는것이 async작업이 끝나기전이라면 기다림
}
// future and promsise
{ // future를 thread에서도 사용하려면 promise을 선언해줘야 한다.
std::promise<int> prom;
auto future = prom.get_future(); // 미래에 데이터를 돌려주겠다는 약속
auto t = std::thread([](std::promise<int>&& prom)
{
prom.set_value(1 + 2);
}, std::move(prom));
cout << future.get() << endl;
t.join();
}
// promise가 set_value를 통해 값을 받을때 까지 future가 기다리고 있다.
{
auto f1 = std::async([] {
cout << "async 1 start\n";
this_thread::sleep_for(std::chrono::seconds(2));
cout << "async 1 end\n";
});
auto f2 = std::async([] {
cout << "async 2 start\n";
this_thread::sleep_for(std::chrono::seconds(1));
cout << "async 2 end\n";
});
cout << "Main function!\n";
// async는 thread와 달리 join이 없어도 문제가 생기지 않음, 둘이 처리방식이 다르다.
// async의 값을 future로 받지 않으면 그냥 순차적으로 실행
}
}19-6 멀티쓰레딩 예제 (백터 내적)
이번시간에는 이전까지 배워왔던 멀티스레드 문법을 사용하여 벡터 내적을 계산하는 예제를 풀어보았다. 설명 생략
19-7 완벽한 전달과 std::forward
std:forward는 완벽한 전달 즉, Perfect Forwarding을 구현할때 사용한다. 우선 문법에 대하여 알아보자.
다음 코드는 이전에 배웠던 R, L 참조의 코드이다.
#include <iostream>
#include <vector>
#include <utility> // std::forward
using namespace std;
struct MyStruct
{};
void func(MyStruct& s)
{
cout << "Pass by L-ref" << endl;
}
void func(MyStruct&& s)
{
cout << "Pass by R-ref" << endl;
}
int main()
{
MyStruct s;
func(s); // L-ref
func(MyStruct()); // R-ref
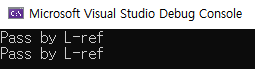
}실행시키면 결과는 우리가 생각한것처럼 작동한다.

func(s); // L-ref
func(MyStruct()); // R-ref위의 코드와 같이 직접적으로 사용하는 방법은 컴파일러가 알아서 R-value 인지 L-value인지 확인해준다.
문제가 되는경우는 템플릿을 사용할때는 구분을 안해준다. 템플릿이 사용된 코드로 변경해 보았다.
struct MyStruct
{};
template <typename T>
void func_wrapper(T t)
{
func(t);
}
void func(MyStruct& s)
{
cout << "Pass by L-ref" << endl;
}
void func(MyStruct&& s)
{
cout << "Pass by R-ref" << endl;
}
int main()
{
MyStruct s;
func_wrapper(s);
func_wrapper(MyStruct());
}우리의 의도는 func_wrapper에서는 L-value ref를 넣고, func_wrapper(MyStruct()) 에는 R-value ref를 넣어 내부에서 func를 실행하면서 오버로딩 된 2개를 구분해주길 기대하지만, 실제로 실행해보면 구분하지 못한다. 왜냐하면 템플릿화 되면서 L-ref 인지 R-lef 인지 정보가 날아가 버린다. 따라서 실행시 둘다 L-ref처럼 작동한다.
이러한 문제를 어떻게 해결해야할까? 이럴때 perfect forward를 사용한다.
perfect forward구현은 매개변수를 R-value ref를 받아오는 것 처럼 && 을 사용한다.
이후 받아온 t를 func로 forwarding을 해줄때 std::forward<T>(t)를 이용하여 전달을 해주게 된다.
std::forward가 하는 일은 t가 들어올때 L-ref로 들어온것 이면, L-value로 return해주고, R-ref로 들어온 것은 R-value를 반환해준다.
template <typename T>
void func_wrapper(T&& t)
{
func(std::forward<T>(t));
}위와 같이 코드를 변경후 다시 실행해 보자.

문법적인 측면에서 어떻게 사용하는지를 알아보았다. 다른 예로 move_semntics의 의미를 좀더 상요해보자.
#include <iostream>
#include <vector>
#include <cstdio>
#include <utility> // std::forward
using namespace std;
class CustomVector {
public:
unsigned n_data = 0;
int* ptr = nullptr;
CustomVector(const unsigned& _n_data, const int& _init = 0)
{
cout << "Consturctor" << endl;
init(_n_data, _init);
}
CustomVector(CustomVector& l_input)
{
cout << "Copy constructor" << endl;
init(l_input.n_data);
for (unsigned i = 0; i < n_data; i++)
ptr[i] = l_input.ptr[i];
}
CustomVector(CustomVector&& r_input)
{
cout << "Move constructor" << endl;
n_data = r_input.n_data;
ptr = r_input.ptr;
r_input.n_data = 0;
r_input.ptr = nullptr;
}
~CustomVector()
{
delete[] ptr;
}
void init(const unsigned& _n_data, const int& _init = 0)
{
n_data = _n_data;
ptr = new int[n_data];
for (unsigned i = 0; i < n_data; i++)
ptr[i] = _init;
}
};
void doSomething(CustomVector& vec)
{
cout << "Pass by L-ref" << endl;
CustomVector new_vec(vec); // copy
}
void doSomething(CustomVector&& vec)
{
cout << "Pass by R-ref" << endl;
CustomVector new_vec(std::move(vec)); // move
}
int main()
{
CustomVector my_vec(10, 1024);
doSomething(my_vec);
doSomething(CustomVector(10, 8));
my_vec;
}실행결과는 다음과 같다.

위의 직전의 코드도 앞의 예와 마찬가지로 템플릿 화 시키면 문제가 발생한다. 이전과 같은 방식으로 코드를 변경해주어야 한다.
template<typename T>
void doSomethingTemplate(T&& vec)
{
doSomething(std::forward<T>(vec));
}
int main()
{
CustomVector my_vec(10, 1024);
doSomethingTemplate(my_vec);
doSomethingTemplate(CustomVector(10, 8)); // R-ref로 들어가 move를 사용
my_vec;
}결과는 다음과 같다.

마지막으로 조금 의아한 점을 살펴보고 마무리 하자.
void doSomething(CustomVector&& vec)
{
cout << "Pass by R-ref" << endl;
CustomVector new_vec(std::move(vec)); // move
}위의 함수를 보면 매개변수가 명확하게 R-ref로써 &&를 사용하고 있으니 함수의 body에서는 std::move를 빼고 사용해도 되는것 아닌가? 라는 생각이 들 수 있다. 다음 코드처럼 말이다.
void doSomething(CustomVector&& vec)
{
cout << "Pass by R-ref" << endl;
CustomVector new_vec(vec);
}하지만 std::move를 안해주고 넘겨버리면 L-value ref로 받아버린다. copy가 호출되버린다.
왜 이런 현상이 나타날까? 사실 vec 그 자체만으로는 변수이기때문에 L-value이다. 따라서 L-value처럼 들어가버리는 것 이다.
따라서 사용시 명확한 move constructor를 호출하겠다는 의미전달을 위해서라도 std::move를 사용하자!
19-8 자료형 추론 auto와 decltype
프로그래머에게 자료형 추론이란 매우 편리한 기능중 하나이다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class Example
{
public:
void ex1()
{
vector<int> vect;
for (vector<int>::iterator itr = vect.begin(); itr != vect.end(); itr++)
cout << *itr;
for (auto itr = vect.begin(); itr != vect.end(); itr++)
cout << *itr;
for (auto itr : vect) // for (const auto & itr : vect)
cout << itr;
}
void ex2()
{
int x = int(); // x is an int, initialized to 0
auto auto_x = x;
const int& crx = x; // auto는 추혼할때 const와 reference를 다 때버림
auto auto_crx1 = crx;
const auto& auto_crx2 = crx; // auto자체는 int고 왼쪽 오른쪽에 붙어서 const int&가 됨
volatile int vx = 1024;
auto avx = vx; // int
volatile auto vavx = vx; // volatile int
}
//template<class T>
//void func_ex3(T arg) { }
template<class T>
void func_ex3(const T& arg) { }
void ex3()
{
const int& crx = 123;
func_ex3(crx);
}
void ex4()
{
const int c = 0;
auto& rc = c; // 갖어오는 변수가 const 라면 당연히 ref도 const가 아니면 갖어올수가 없다.
// rc = 123; error!
}
void ex5()
{
int i = 42;
auto&& ri_1 = i; // ri_1는 l-value : 왜냐하면 들어온것이 l-value니까
auto&& ri_2 = 42; // ri_2는 r-value
}
void ex6()
{
int x = 42;
const int* p1 = &x;
auto p2 = p1; // int*가 아닌, const int * 까지 다 가져왔다
// 포인터일 경우에는 auto가 다 가져온다
}
template<typename T, typename S>
void func_ex7(T lhs, S rhs)
{
auto prod1 = lhs * rhs; // 곱한값의 자료형이 무엇일지 알기 힘들다.
typedef decltype(lhs* rhs) product_type; // 실제로 계산이 수행되지않고 추론만한다.
product_type prod2 = lhs * rhs;
decltype(lhs * rhs) prod3 = lhs * rhs; // 바로 사용도 가능
}
template<typename T, typename S>
auto func_ex8(T lhs, S rhs) -> decltype(lhs* rhs)
{
return lhs * rhs;
}
void ex7_8()
{
func_ex7(1.0, 345);
func_ex8(1.2, 345);
}
struct S
{
int m_x;
S()
{
m_x = 42;
}
};
void ex9()
{
int x;
const int cx = 42;
const int& crx = x;
const S* p = new S();
auto a = x;
auto b = cx;
auto c = crx;
auto d = p;
auto e = p->m_x;
// 변수가 선언이 된것을 그대로 갖어오는 decltype
typedef decltype(x) x_type; // x_type = int
typedef decltype(cx) cx_type; // cx_type = const int
typedef decltype(crx) crx_type; // crx_type = const int &
typedef decltype(p->m_x) m_x_type; // m_x_type = int, 'declared' type
// 괄호가 하나더 추가되면 refernce가 붙는다.
typedef decltype((x)) x_with_parens_type; // x_with_parens_type = int &
typedef decltype((cx)) cx_with_parens_type; // cx_with_parens_type = const int &
typedef decltype((crx)) crx_with_parens_type; // crx_with_parens_type = const int &
typedef decltype((p->m_x)) m_x_with_parens_type;// m_x_with_parens_type = const int &
}
const S foo() { return S(); }
const int& foobar() { return 123; }
void ex10()
{
vector<int> vect = { 42, 43 };
auto a = foo(); // a = S
typedef decltype(foo()) foo_type; // foo_type = const S
auto b = foobar(); // b = int
typedef decltype(foobar()) foobar_type; // foobar_type = const int &
auto itr = vect.begin(); // itr = std::vector<int>::iterator
typedef decltype(vect.begin()) iterator_type; // iterator_type = std::vector<int>::iterator
auto first_element = vect[0]; // firstElement = int
decltype(vect[1]) second_element = vect[1]; // secondElement = int&
}
void ex11()
{
int x = 0;
int y = 0;
const int cx = 42;
const int cy = 43;
double d1 = 3.14;
double d2 = 2.72;
typedef decltype(x* y) prod_xy_type; // prod_xy_type = int
auto a = x * y; // a = int
typedef decltype(cx* cy) prod_cxcy_type; // prod_cxcy_type = int
auto b = cx * cy; // b = int
// l-value일때는 &가 추가됨
typedef decltype(d1 < d2 ? d1 : d2) cond_type; // cond_type = double&
auto c = d1 < d2 ? d1 : d2; // c = double
typedef decltype(x < d2 ? x : d2) cond_type_mixed; // cond_type_mixed = double
auto d = x < d2 ? x : d2; // d = double
// auto d = std::min(x, d2); = error! 두 argument의 type이 다르면 작동안함.
}
template<typename T, typename S>
auto fpmin_wrong(T x, S y) -> decltype(x < y ? x : y)
{
return x < y ? x : y;
}
template<typename T, typename S> // 자료형이 같을 경우 &가 붙는 단점을 보완.
auto fpmin(T x, S y) ->
typename std::remove_reference<decltype(x < y ? x : y)>::type
{ return x < y ? x : y; }
void ex12()
{
int i = 42;
double d = 45.1;
auto a = std::min(static_cast<double>(i), d);
int& j = i;
typedef decltype(fpmin_wrong(d, d)) fpmin_return_type1;
typedef decltype(fpmin_wrong(i, d)) fpmin_return_type2;
typedef decltype(fpmin_wrong(j, d)) fpmin_return_type3;
}
void ex13()
{
vector<int> vec;
typedef decltype(vec[0]) integer; // decltyp은 실제로 수행하지는 않으므로 문제 X
}
template<typename R>
class SomeFunctor
{
public:
typedef R result_type;
SomeFunctor()
{ }
result_type operator() () { return R; }
};
void ex14()
{
SomeFunctor<int> func;
typedef decltype(func)::result_type integer; // integer = int
}
void ex15()
{
auto lambda = []() {return 42; };
decltype(lambda) lambda2(lambda); // func2 = func; copy해서 가져온다.
decltype((lambda)) lambda3(lambda); // &func3 = func; ref해서 가져온다.
cout << "lambda functions" << endl;
cout << &lambda << " " << &lambda2 << endl;
cout << &lambda << " " << &lambda3 << endl;
}
void ex16()
{
// generic lambda;
auto lambda = [](auto x, auto y) {return x + y; };
cout << lambda(1.1, 2) << " " << lambda(3, 4) << lambda(4.5, 2.2) << endl;
// 람다 함수는 parameter로 auto를 사용가능
}
};
int main()
{
Example ex;
ex.ex1();
ex.ex2();
ex.ex3();
ex.ex10();
ex.ex11();
ex.ex12();
ex.ex14();
ex.ex15();
ex.ex16();
}
2) 나의 현황
● 마지막 20강은 듣기만 할 예정이다.
'CS > C++' 카테고리의 다른 글
| 뇌를 자극하는 C++ STL : 1장. 연산자 오버로딩 (0) | 2022.01.18 |
|---|---|
| C++ 공부 섹션20 : 홍정모의 따배씨쁠쁠 <완강> (0) | 2022.01.18 |
| C++ 공부 섹션18 입출력 : 홍정모의 따배씨쁠쁠 (0) | 2022.01.17 |
| C++ 공부 섹션17 String : 홍정모의 따배씨쁠쁠 (0) | 2022.01.17 |
| C++ 공부 섹션16 STL : 홍정모의 따배씨쁠쁠 (0) | 2022.01.17 |
댓글