
1. 문제의 상황
여러 개의 독립된 Order Service가 동작하고 있는 상황에서, 각 OrderService마다 DB를 할당하게 된다면 동기화 작업이 힘들어진다.
예를 들어 초콜릿의 재고가 초기에 10이었을 때, OrderService A에 주문이 들어와 3개가 감소하여 7개가 되었다 생각해 보자.
하지만 OrderService B에 할당된 DB에는 여전히 재고가 10개 있으며, 이는 DB 간의 데이터 동기화를 어렵게 만드는 주범이 될 것이다!
예를 들면 다음과 같은 것이다!

현재 사이드로 구현 중인 미니 프로젝트에서
UserService에서 주문 요청 -> Service Discovery를 통해 해당 서비스 찾기 -> 해당 OrderService에 주문 요청을 하게 된다.
2개의 OrderService 중 어떤 서비스가 요청을 받는지에 따라서 DB가 차이 나버리게 된다.
이를 Kafka를 통해 동기화시켜보자!
2. 해결하기
나의 경우 Kafka Connect Sink를 통해서 DB에 바로 영속화시키도록 구현하였다.
이를 그림으로 보면 다음과 같다.

사실상 Producer의 입장에서는 DB가 아닌 Kafka만을 바라보게 되고, DB입장에서도 여러 Service가 아닌 하나으 Kafka만을 바라보게 되니, 중간에서 일종의 인터페이스 + buffer 역할을 해준다 생각된다.
2 - 1) Kafka와 Zookeeper 실행
몇 가지 커멘드를 살펴봅시다.
Zookeeper 및 kafka 서버 구동
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
./bin/kafka-server-start.sh ./config/server.properties
Topic 생성 (간단하게 partition은 1개만)
./bin/kafka-topics.sh --create --topic orders --bootstrap-server localhost:9092 --partitions 1
Topic 목록 확인
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
Topic 정보 확인
./bin/kafka-topics.sh --describe --topic orders --bootstrap-sever localhost:9092
메시지 생산 테스트
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic quickstart-events
메시지 소비 테스트
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic quickstart-events --from-beginning우리는 이중 Zookeeper와 Kafka만 우선 서버에 실행시켜 준다.
2 - 2) Kafka와 MariaDB 연동
카프카와 통신하기 위해서 Kafka Connect를 설치하겠습니다. Kafka 홈페이지로 이동하여 다운로드합니다!
저는 6.1.0 버전 tar파일을 다운로드하였습니다. 아래 명령어로 압축 해제하고 해당 폴더(/confluent-6.1.0)로 이동합니다.
tar xvf confluent-community-6.1.0.tar.gz
우선 파일의 압축을 해제하였으니, JDBC Connector를 설정해야 합니다.
Connector로는 JDBC connector를 사용하겠습니다. JDBC connector 여기서 다운로드하고 작업 중인 Kafka 폴더내부로 옮겨서 압축 해제합니다.
이후 JDBC connect를 사용하기 위해서 플러그인 경로를 설정해야 합니다.
./etc/kafka/connect-distributed.properties 파일 맨 밑에 한 줄 추가해 주면 됩니다!

위에 경로에도 보이듯, 저 같은 경우 Kafka 파일 내부에 connect파일을 함께 두었습니다.
마지막으로, JDBC connector가 MariaDB를 사용하기 위해서 현재 사용 중인 MariaDB 드라이버 정보가 필요합니다.
저 같은 경우 기존의 Gradle에서 다운로드한 library 목록에서 복사해 오게 되었습니다.
위 경로로 이동하여 jar파일 자체를 복사하여 confluentic-kafka-connect-jdbc-10.7.3/lib/ 하위로 복사하였습니다.
이제 kafka connect 실행합니다.
./bin/connect-distributed ./etc/kafka/connect-distributed.properties

성공적으로 connect가 실행되는 것을 확인할 수 있게 되었습니다!
이후 Kafka의 Connectors를 REST API를 통해 생성해 주면 됩니다!
다음과 같이 order-sink-connect라는 이름으로 connect를 만들면서, orders라는 topic을 생성하였습니다!

이후 connectors조회 api를 통해 생성된 것을 확인할 수 있다.

2 - 3) Producer 코드
kafka factory와 template코드는 생략...
▶ OrderProducer 코드
@Slf4j
@Service
public class OrderProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
private final ObjectMapper objectMapper;
private final Schema schema;
public OrderProducer(KafkaTemplate<String, String> kafkaTemplate, ObjectMapper objectMapper) {
this.kafkaTemplate = kafkaTemplate;
this.objectMapper = objectMapper;
schema = buildSchema();
}
public void send(String topic, OrderDto orderDto) {
OrderKafkaDto kafkaOrderDto = new OrderKafkaDto(schema, orderDto.toPayload());
try {
String jsonInString = objectMapper.writeValueAsString(kafkaOrderDto);
kafkaTemplate.send(topic, jsonInString); // Producer가 메시지 생성
log.info("Order Producer sent data from the Order microservice: " + kafkaOrderDto);
} catch (JsonProcessingException ex) {
log.error("Order Producer couldn't send data from the Order microservice: " + kafkaOrderDto);
}
}
private Schema buildSchema() {
return Schema.builder()
.type("struct")
.fields(buildFields())
.optional(false)
.name("orders")
.build();
}
private List<Field> buildFields() {
return Arrays.asList(new Field("string", true, "order_id"),
new Field("string", true, "user_id"),
new Field("string", true, "product_id"),
new Field("int32", true, "qty"),
new Field("int32", true, "unit_price"),
new Field("int32", true, "total_price"));
}
}
2 - 4) 데이터 전송해 보기
우선 다음과 같이 Api-gateway 1개, order-service 2개, user-service 1개가 기동 중이다.

총 3번의 주문 API를 호출하였다. 다음 호출 순서대로 로그에 남게 된다.
# 1번 주문
{
"productId": "CATALOG-001",
"quantity": 7,
"unitPrice": 11000
}
# 2번 주문
{
"productId": "CATALOG-002",
"quantity": 4,
"unitPrice": 71000
}
# 3번 주문
{
"productId": "CATALOG-002",
"quantity": 1,
"unitPrice": 6000,
"totalPrice": 6000,
"orderId": "77a436fd-64f9-4d35-999b-a957195f5d23"
}
API-gatgeway가 round-robin방식으로 돌면서 요청을 위임하기 때문에 OrderService1에 1, 3번 주문이 도달하였고,

OrderService2에 2번 주문이 도달하게 되었다!

그럼 DB에는 어떻게 기록되었을까??

동일한 id의 User가 주문한 내역이 모두 성공적으로 하나의 DB에서 처리되게 되었다!!!
초기 목표로 하였던 서비스 간의 DB동기화를 kafka를 통해 성공한 것이다!
3. 정말 한 번만 저장될까?
공식문서를 살펴보던 도중 다음과 같은 부분을 읽어볼 수 있었다.

그렇다 at least once라는 부분이 매우 거슬린다. 최소 한 번이라는데, 이는 2번 중복하여 저장될 수 있다는 말을 내포하고 있다....
https://docs.confluent.io/kafka-connectors/jdbc/current/source-connector/overview.html
JDBC Source Connector for Confluent Platform | Confluent Documentation
The Kafka Connect JDBC Source connector allows you to import data from any relational database with a JDBC driver into an Apache Kafka® topic. This connector can support a wide variety of databases. Data is loaded by periodically executing a SQL query and
docs.confluent.io
그럼 이를 어떻게 보완해야 할까?
kafka의 경우 sink connector를 생성할 때, insert.mode를 이용하여 insert를 할지 update를 할지 선택할 수 있다고 한다.
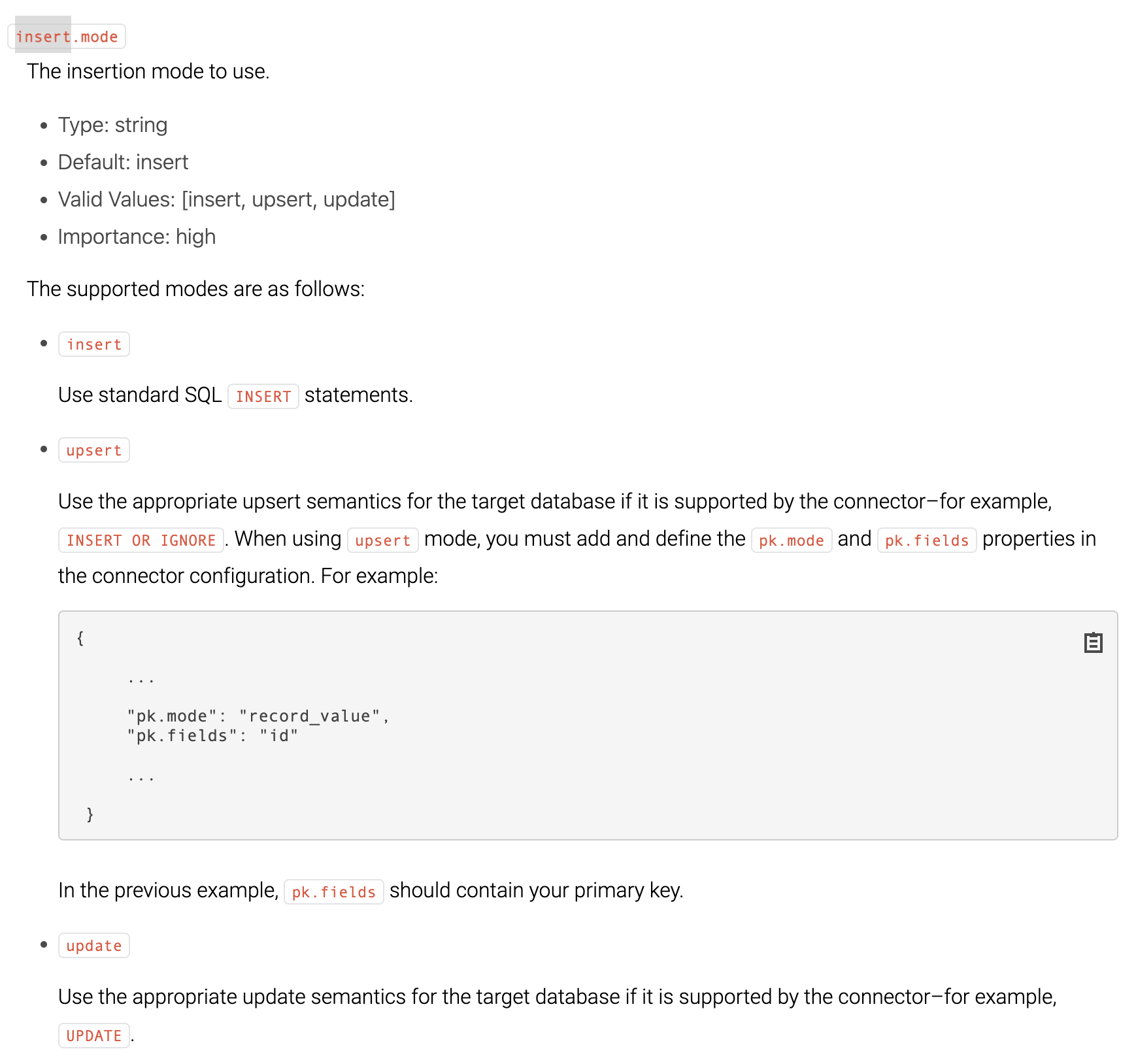
update를 할 때의 경우, 기존 데이터의 저장된 시간과 차이가 있을 경우에 업데이트하게 되는데, 이를 위해 update date 칼럼을 추가하면서 같이 지정해 주면 해결 가능하다고 한다.
즉, millisecond단위로 확인하여 진짜 다른 경우에만 삽입하도록 하면 중복데이터가 삽입될 일이 없을 것이다!
'BackEnd > Kafka' 카테고리의 다른 글
| [Kafka] Kafka Connect on Docker (2) | 2023.12.06 |
|---|
댓글