내가 공부한 것을 올리며, 중요한 단원은 저 자신도 곱씹어 볼 겸 상세히 기록하고 얕은 부분들은 가볍게 포스팅하겠습니다.

5. 주문 조회 V4: JPA에서 DTO 직접 조회
이번 시간에는 DTO를 직접 반환하도록 코드를 변경해 보자.
join을 해도 tuple의 수가 증가하지 않는 ToOne 관계는 JOIN으로 최적화 하기 쉬우므로 한번에 조회하고,
ToMany 관계는 최적화 하기 어려우므로 findOrderItems() 같은 별도의 메서드를 만들어 처리할 것 이다.
우선 컨트롤러는 다음과 같다.
@GetMapping("/api/v4/orders")
public List<OrderQueryDto> ordersV4() {
return orderQueryRepository.findOrderQueryDtos();
}여기서 잠시 디렉토리 구조에 대하여 알아보자.
우리가 만들게 될 OrderQueryDto는 query라는 디렉토리에 별로도 만들어 주었다.
또한 OrderQueryDto를 바로 반환해주는 OrderQueryRepository또한 query 디렉토리 안에 있다.
즉, query 디렉토리는 특정 화면이나, API 스펙에 의존적인 조회를 위해 사용되는 특화된 디렉토리이다.
핵심 Entity같은 경우 OrderRepository 를 통해 조회할수 있다.
반환하는데 사용되는 DTO는 다음과 같다.
@Data
public class OrderQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemQueryDto> orderItems;
public OrderQueryDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
}
}
@Data
public class OrderItemQueryDto {
private Long orderId;
private String itemName;
private int orderPrice;
private int count;
public OrderItemQueryDto(Long orderId, String itemName, int orderPrice, int count) {
this.orderId = orderId;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
}
이제 Repository를 작성해보자. orderQueryRepository를 만들것 이다.
조금 코드가 복잡하다.
@Repository
@RequiredArgsConstructor
public class OrderQueryRepository {
private final EntityManager em;
public List<OrderQueryDto> findOrderQueryDtos() {
List<OrderQueryDto> result = findOrders(); // collection 부분을 제외하고 2개의 order 가져옴 (1 쿼리)
result.forEach(o -> { // 각각의 order에 대하여
List<OrderItemQueryDto> orderItems = findOrderItems(o.getOrderId()); // orderItems를 찾아오기 (N 쿼리)
o.setOrderItems(orderItems); // 기존의 order에 orderItems setting해주기
});
return result;
}
private List<OrderItemQueryDto> findOrderItems(Long orderId) {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count) " +
"from OrderItem oi " +
"join oi.item i " +
"where oi.order.id = :orderId", OrderItemQueryDto.class
).setParameter("orderId", orderId)
.getResultList();
}
private List<OrderQueryDto> findOrders() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderQueryDto(o.id, m.name, o.orderDate, o.status, d.address) " +
"from Order o " +
"join o.member m " +
"join o.delivery d", OrderQueryDto.class
).getResultList();
}
}실행 결과는 다음과 같다.
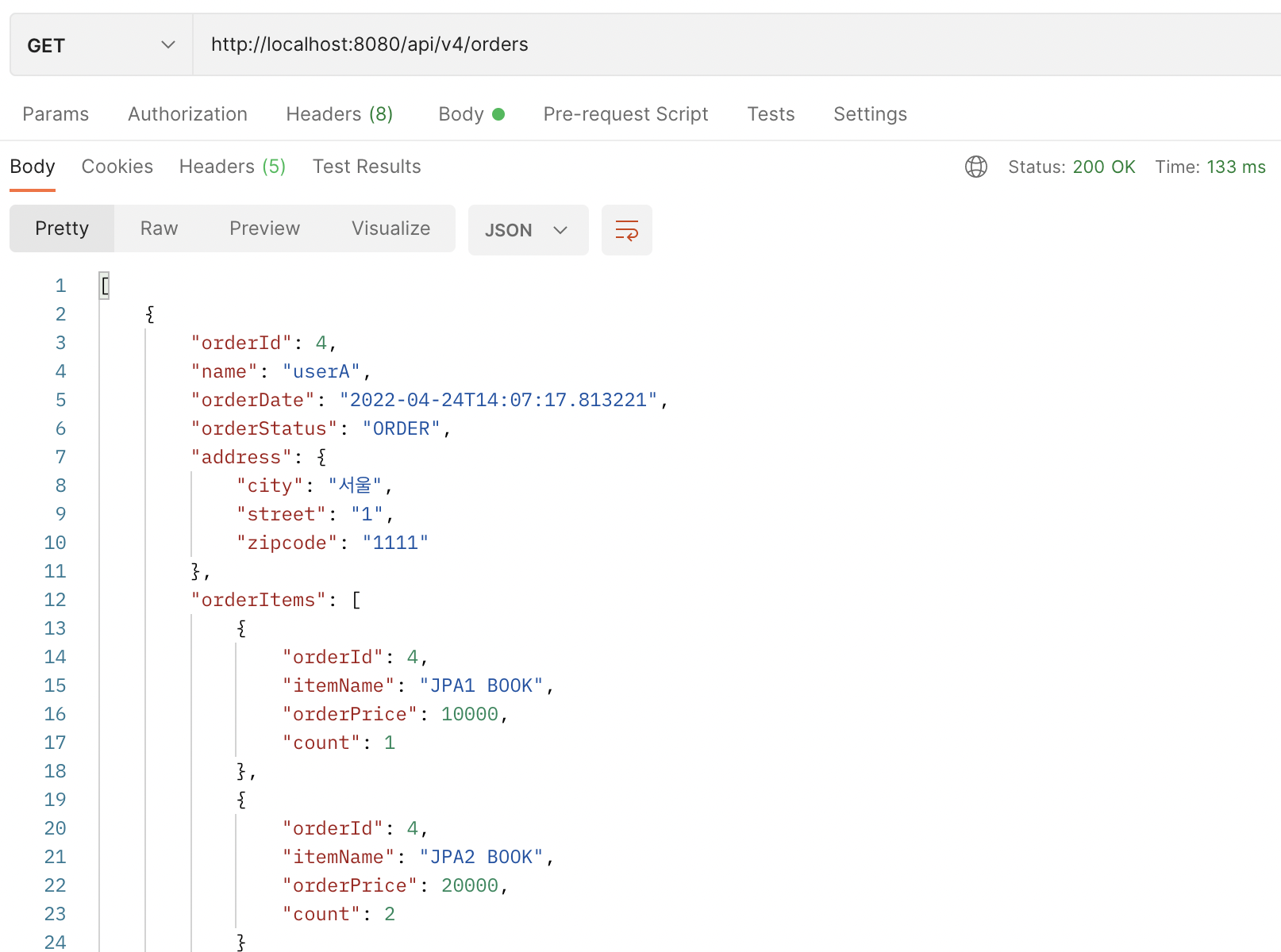
4, 11번 주문 2건 모두 정상 조회된다.
1) 맨 처음 order, member, deliver 를 그냥 join 하여 가져오는 쿼리 1번
select
order0_.order_id as col_0_0_,
member1_.name as col_1_0_,
order0_.order_date as col_2_0_,
order0_.status as col_3_0_,
delivery2_.city as col_4_0_,
delivery2_.street as col_4_1_,
delivery2_.zipcode as col_4_2_
from
orders order0_
inner join
member member1_
on order0_.member_id=member1_.member_id
inner join
delivery delivery2_
on order0_.delivery_id=delivery2_.delivery_id
2) OrderItem 과 Item을 가져오기 위해 join한다. (User A의 order)
이는 findOrderItems() 메서드를 호출할 때 발생하게 된다. join하여 OrderItem 과 Item을 한번에 select 하게 된다.
select
orderitem0_.order_id as col_0_0_,
item1_.name as col_1_0_,
orderitem0_.order_price as col_2_0_,
orderitem0_.count as col_3_0_
from
order_item orderitem0_
inner join
item item1_
on orderitem0_.item_id=item1_.item_id
where
orderitem0_.order_id=?
3) OrderItem 과 Item을 join한다. (User B의 order)
select
orderitem0_.order_id as col_0_0_,
item1_.name as col_1_0_,
orderitem0_.order_price as col_2_0_,
orderitem0_.count as col_3_0_
from
order_item orderitem0_
inner join
item item1_
on orderitem0_.item_id=item1_.item_id
where
orderitem0_.order_id=?총 3번의 쿼리가 나가게 되었다. 1 + N 의 문제가 발생해 버렸다.
findOrders()라는 메서드를 1번 실행했는데(예시에서는 Order 2건 나옴) findOrderItems가 추가로 2번 실행되었다.
만약 주문이 N건 조회 됬다면 findOrderItems() 또한 N번 실행되게 된다.
Query: 루트 1번, 컬렉션 N 번 실행
다음 글에서 DTO를 사용하면서 최적화를 하는 방법에 대하여 알아보자!
6. 주문 조회 V5: JPA에서 DTO 직접 조회 - 컬렉션 조회 최적화
이번 글 에서는 Collection을 DTO로 가져오면서 최적화를 진행해보자.
직전 글 에서 본 코드는 Loop를 돌때마다 query를 날리는데, 이번 버전에서는 쿼리는 1번 날리고 메모리에 Map으로 다 가져온 후 OrderItem을 setting해준다.
이렇게 하면 쿼리가 총 2번 나가게 된다.
컨트롤러는 다음과 같다.
@GetMapping("/api/v5/orders")
public List<OrderQueryDto> ordersV5() {
return orderQueryRepository.findAllByDtoOptimization();
}repository의 findAllByDtoOptimization 메서드는 다음과 같다.
@Repository
@RequiredArgsConstructor
public class OrderQueryRepository {
private final EntityManager em;
public List<OrderQueryDto> findAllByDtoOptimization() {
List<OrderQueryDto> result = findOrders(); // 이전과 동일하게 Collection부분을 제외한 Order 2개를 가져옴
List<Long> orderIds = result.stream()
.map(o -> o.getOrderId()) // orderId 로 변경
.collect(Collectors.toList()); // orderId만 추출
List<OrderItemQueryDto> orderItems = em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count) " +
"from OrderItem oi " +
"join oi.item i " +
"where oi.order.id in :orderIds", OrderItemQueryDto.class)
.setParameter("orderIds", orderIds) // in 쿼리를 통해 OrderItems를 조회
.getResultList();
Map<Long, List<OrderItemQueryDto>> orderItemMap = orderItems.stream()
.collect(Collectors.groupingBy(orderItemQueryDto -> orderItemQueryDto.getOrderId())); // Map으로 변경
result.forEach(o -> o.setOrderItems(orderItemMap.get(o.getOrderId()))); // result에 ordetItems를 setting해주기
return result;
}
private List<OrderQueryDto> findOrders() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderQueryDto(o.id, m.name, o.orderDate, o.status, d.address) " +
"from Order o " +
"join o.member m " +
"join o.delivery d", OrderQueryDto.class
).getResultList();
}
}실행 결과는 이전과 동일하다.
생성된 쿼리를 보면 다음과 같다. 우선 order, member, delivery에 대한 정보만 가져오는 부분이다.
Order를 가져올때 member 와 delivery를 join하여 가져오는 쿼리는 당연하다.

위 쿼리에서는 OrderItems에 대한 부분은 제외하고 데이터를 가져올 수 있다.
select orderitem0_.order_id as col_0_0_,
item1_.name as col_1_0_,
orderitem0_.order_price as col_2_0_,
orderitem0_.count as col_3_0_
from order_item orderitem0_
inner join item item1_
on orderitem0_.item_id=item1_.item_id
where orderitem0_.order_id in (4 , 11);이후 in 쿼리를 통해서 데이터를 가져온다.
위 코드를 보면 다음과 같은 부분이 있었다.
Map<Long, List<OrderItemQueryDto>> orderItemMap = orderItems.stream()
.collect(Collectors.groupingBy(orderItemQueryDto -> orderItemQueryDto.getOrderId())); // Map으로 변경
// 메모리 상에 OrdetItem에 대한 정보가 모두 로딩되었다.
result.forEach(o -> o.setOrderItems(orderItemMap.get(o.getOrderId())));
return result;메모리 상에 이미 로딩되어있는 orderItemMap이라는 Map을 통해 result로 가져오게 된다.
한번의 쿼리로 메모리에 전부 올리게 된다.
Query: 루트 1번, 컬렉션 1 번 실행
ToOne 관계들을 먼저 조회하고, 여기서 얻은 식별자 orderId로 ToMany 관계인 OrderItem 을 한꺼번에 in쿼리로 조회
MAP을 사용해서 매칭 성능 향상(O(1))
다음시간에는 쿼리 1번으로 조회하는 방법에 대하여 알아보자!
'BackEnd > JPA' 카테고리의 다른 글
| [JPA] Open Session In View (OSIV) (0) | 2022.04.24 |
|---|---|
| [JPA] 컬렉션 조회 최적화 - 4 (0) | 2022.04.24 |
| [JPA] 컬렉션 조회 최적화 - 2 (0) | 2022.04.23 |
| [JPA] 컬렉션 조회 최적화 - 1 (0) | 2022.04.22 |
| [JPA] 지연 로딩과 조회 성능 최적화 - 2 (0) | 2022.04.20 |
댓글