해당 본문은 학교수업시간에 배운 강의내용을 기반으로 정리하는 요약글 입니다. 정확하지 않은 점이 있으면 지적해주시면 감사하겠습니다.
String Matching
string에서 내가 원하는 문자열을 찾는 방법을 말한다.
예를 들어 abababcabcabcdabccbaabdabcabcdabcd 라는 Text가 있다고 해보자. 우리는 이중에서 abcabcd 라는 pattern을 찾아야 한다.
수업시간에는 총 3가지 알고리즘을 알려주셨다.
1) Naive
2) DFA (Deterministic Finite Automaton)
3) KMP (Knuth, Morris, Pratt)
이중 가장 빠른 알고리즘은 KMP 알고리즘 이며, 만약 ∑가 작은경우라면 DFA알고리즘이 더 좋을 수 있다.
(참고로 ∑는 알파벳의 집합을 의미한다, 예를 들어 ∑ = {a, b, c, d, e} 와 같이 말이다)
Naive
Naive 알고리즘은 한칸씩 이동하면서 단순 비교를 반복하는 가장 직관적인 알고리즘 이다.
각 글자마다 어떤 값을 계산해야 한다. 여기서 어떤 값 이란, "Text의 모든 자리마다 match가 되도록 가장 길게 놓을 수 있는 pattern의 앞부분의 길이"를 말한다.
위에서 살펴본 예를 일부분 이용해보면 다음과 같아진다.
|
1
|
2
|
1
|
2
|
1
|
2
|
3
|
4
|
5
|
6
|
4
|
5
|
6
|
7
|
1
|
2
|
3
|
0
|
0
|
|
a
|
b
|
a
|
b
|
a
|
b
|
c
|
a
|
b
|
c
|
a
|
b
|
c
|
d
|
a
|
b
|
c
|
c
|
b
|
|
|
|
|
|
|
|
|
a
|
b
|
c
|
a
|
b
|
c
|
d
|
|
|
|
|
|
3행이 pattern을 나타낸 것 이다. 위의 7이 써있는 d의 경우 d앞의 6글자 또한 페턴과 일치한다.
가장 길게 놓을 수 있는 앞부분의 길이가 7이 되며 페턴과 일치하는 부분을 찾은 예가 된다.
int naivematch(char T[], int n, char P[], int output[])
{
int i, j, k, kk; // output은 모두 0으로 초기화
for(i = 0; i < n; i++){
for(j = i, k = 0; k < m; j++, k++)
if(T[j] != P[k]) break;
for(j = i, kk = 0; kk < k; j++, kk++)
output[j] = max(output[j], kk+1);
}
}위의 코드에서 i는 text에서의 시작위치, j는 text상에서의 위치, k는 pattern상에서의 위치 를 알려준다.
또한 output 배열에서 max값으로 덮어 씌워주고 있는데 이는 이전에 써있는 값이 있을 수 있기 때문이다.
N : text 문자열 길이 / M : 찾으려는 pattern 문자열 길이
시간복잡도 : O(MN), 총 text길이 N만큼 반복하는데 각 알파벳 마다 최대 M번 비교 해야함.
공간복잡도 : O(N) (or O(1))
DFA
DFA 방식에서는 DFA table이 주어진다고 가정한 후 설명해 주셨다.
원래는 table을 만드는 코드 또한 구현해야 하지만 우리 수업에서는 table은 주어진다고 가정하였다.
다음 table을 먼저 확인해 보자.

이 table의 의미하는 바는 다음과 같다.
어떤 숫자(행) 가 알파벳 위에 있다면, 다음 글자(열)가 무엇일때 어떤 숫자를 적으면 되는지 table에서 알려주고 있다.
|
0
|
1
|
2
|
1
|
2
|
1
|
2
|
3
|
4
|
5
|
6
|
4
|
5
|
6
|
7
|
1
|
2
|
3
|
0
|
0
|
|
|
a
|
b
|
a
|
b
|
a
|
b
|
c
|
a
|
b
|
c
|
a
|
b
|
c
|
d
|
a
|
b
|
c
|
c
|
b
|
가령 위의 표 나와있는 text의 가장 맨 처음 시작은 0이다. 다음 글자는 a로이다. 따라서 table에서 0행 a열을 보면 값 1이 나온다. 이값이 a위에 적히는 숫자이다.
같은 방식으로 계속 나아가다가 주황글씨로 된 d 한칸 앞인 c에 도착했다고 해보자. c위의 숫자가 6이며 다음 알파벳이 d이다 따라서 6행 d열을 표에서 보면 7이 나오고 match되는 pattern을 text 상에서 찾은 것 이다.
int DFAmatch(char T[], int n, int output[]) {
int i, s;
s = 0; // 0번 상태에서 시작
for (i = 0; i <= n; i++) { // 첫번째 글자부터 확인
s = Table[T[i] - 'a'][s];
output[i] = s;
}
}위의 코드에서 i는 현재 읽고있는 글자의 text에서의 위치, s는 현재 상태 번호이다. 코드는 0번 상태부터 시작한다.
또한 table에서의 행, 열 정보를 통해 접근하기 위해서 Table[T[i] - 'a'][s]와 같이 접근한다.
T[i]는 현재 글자를 의미하는데, 현재글자에서 'a'의 ASCII값을 빼면 index값을 얻을 수 있기 때문이다.
시간복잡도 : O(ΣM + N), DFA 테이블 제작시간 + text읽는 시간
공간복잡도 : O(ΣM), DFA 테이블 공간
KMP
DFA의 table에서 ∑를 줄이러면 어떻게 해야할까? 다음 글자가 pattern과 일치하는지만 확인하면 되는 것 아닐까?
이로부터 나온 방식이 KMP 알고리즘 이다.
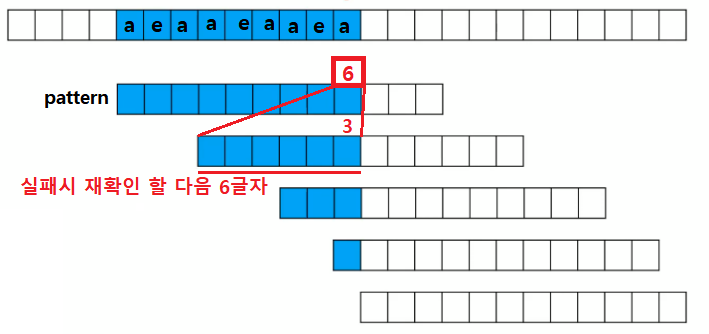
위의 그림을 보면 빨간 박스안에 6이 적혀있는것을 볼 수 있다. 6이 의미하는 바가 무엇일까?
6이 적혀있는 페턴은 9글자 까지는 text와 일치하고, 다음 10번째 글자를 비교해서 다를 경우 6글자 까지 match된다 생각하고 retry 하라는 의미이다.
9글자가 match되는 상태에서 3칸만 옆으로 밀면 6글자가 겹칠수 있기때문에 6이 쓰인다. 만약 6글자 다음 글자인 7번째 글자에서 비교후 실패한다면 3칸을 더 밀어서 다음 3칸과 재 비교를 한다. 두번째 페턴에서 6번째 칸 위에 3이 적혀있는 것 이다.
이를 Failure function 이라고 한다.
● Failure function의 정의
pattern P의 앞부분 k글자까지 매치 되었을 때 다음 번 시도할 pattern앞 부분의 길이를 구해준다.
int f[8] = {-1,0,1,1,2,2,3,4,5,6,8,4,1};
int KMPmatch(char T[], int n, char P[], int m, int output[]) {
int i, s; // i는 피탐색 문자열의 인덱스, s는 직전자리에서 겹치는 수
i = 0; s = 0;
output[i] = s;
while (i <= n) {
if (s == 0) { // 겹치는것이 없으면 (첫 시작이면)
if (T[i] != P[s+1]) { output[i] = 0; i++; s = 0;} // 현재문자와 검색대상 문자열의 다음 문자가 다름 <완전실패>
// 0을 표기한 뒤, 다음 글자로 한칸 전진한다.
else {output[i] = 1; i++;; s = 1} // 현재문자와 검색대상 문자열의 다음 문자가 같다면? <성공>
// output에 1을 표기한 뒤, 문자열은 한칸 전진. s는 이제 1.
}
else { // 표기된 것이 있으면
if (T[i] == P[s+1]) {output[i] = s+1; i++; s++;} // 현재문자와 검색대상 문자열의 다음 문자가 같다면? <성공>
// 1을 표기한 뒤, 문자열의 다음 문자를 찾고 s를 늘린다.
else {s = f[s];} // 현재문자와 검색대상 문자열의 다음 문자가 같다면? <실패>
// 현재 문자열에 대해서는 아무 작업도 하지않고, Failure Function을 통해 s값만 줄인다.
// 같은 문자에 대해 재시도를 하게 된다.
}
}
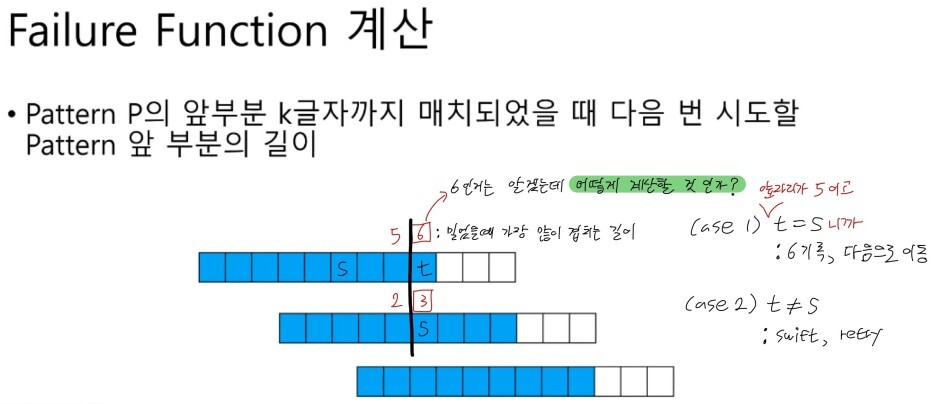
}이제 6을 왜 적는지는 알게된 것 같다. 그럼 이 6은 어떻게 구하는 것 일까? 다음 사진에서의 필기를 확인해 달라.
성능 분석은 어떻게 해야할까?
우선 위의 코드에서 보면 크게 3부분으로 나눠진 결과를 볼 수 있다. 실패, 완전실패, 성공
- 완전 실패는 완전하게 실패하고 한칸 전진하는 경우이다.
- 그냥 실패는 해당 알파벳 자리에서 위에 6을 확인한후 실패시 그다음 3을, 다시 실패시 그다음 1을 ... 이런식으로 계속 실패했다 재확인 하는 과정중의 실패를 말한다.
- 성공은 말 그대로 성공한 케이스 이다.
text에서 각 글자당 성공, 완전실패는 하나만 가능하다. 따라서 text가 n개이니 성공, 완전실패는 다합해서 n번 가능하다.
그냥 실패의 경우 text에서 각 글자당 여러번이 가능하다. 실패한번할 경우 pattern을 옆으로 한칸 밀어본후 확인하는데 총 n번 밀수있다. 검색대상의 길이가n이기 때문이다.
시간복잡도 : O(m + n), failure func를 만드는 시간 m, 성공 및 완전실패, 실패의 합 2n 정리하면 m + n
공간복잡도 : O(m), failure func의 공간
'CS > Data Structure (2021-1)' 카테고리의 다른 글
| [자료구조] Equivalence Relation (0) | 2022.01.24 |
|---|---|
| [자료구조] Stack, Queue (0) | 2022.01.24 |
| [자료구조] 배열의 성능 분석 (0) | 2022.01.24 |
| [자료구조] Merge Sort 증명 (0) | 2022.01.23 |
| [자료구조] Selection Sort 증명 (0) | 2022.01.22 |
댓글